互联网协议和Goweb编程
[toc]
前言
互联网的核心是一系列协议,总称为” 互联网协议”(Internet Protocol Suite),正是这一些协议规定了电脑如何连接和组网。
互联网的核心是一系列协议,总称为” 互联网协议”(Internet Protocol Suite),正是这一些协议规定了电脑如何连接和组网。我们理解了这些协议,就理解了互联网的原理。由于这些协议太过庞大和复杂,没有办法在这里一概而全,只能介绍一下我们日常开发中接触较多的几个协议。
互联网分层模型
互联网的逻辑实现被分为好几层。每一层都有自己的功能,就像建筑物一样,每一层都靠下一层支持。用户接触到的只是最上面的那一层,根本不会感觉到下面的几层。要理解互联网就需要自下而上理解每一层的实现的功能。
如上图所示,互联网按照不同的模型划分会有不用的分层,但是不论按照什么模型去划分,越往上的层越靠近用户,越往下的层越靠近硬件。在软件开发中我们使用最多的是上图中将互联网划分为五个分层的模型。
物理层
我们的电脑要与外界互联网通信,需要先把电脑连接网络,我们可以用双绞线、光纤、无线电波等方式。这就叫做” 实物理层”,它就是把电脑连接起来的物理手段。它主要规定了网络的一些电气特性,作用是负责传送 0 和 1 的电信号。
数据链路层
单纯的 0 和 1 没有任何意义,所以我们使用者会为其赋予一些特定的含义,规定解读电信号的方式:例如:多少个电信号算一组?每个信号位有何意义?这就是” 数据链接层” 的功能,它在” 物理层” 的上方,确定了物理层传输的 0 和 1 的分组方式及代表的意义。早期的时候,每家公司都有自己的电信号分组方式。逐渐地,一种叫做” 以太网”(Ethernet)的协议,占据了主导地位。
以太网规定,一组电信号构成一个数据包,叫做” 帧”(Frame)。每一帧分成两个部分:标头(Head)和数据(Data)。其中” 标头” 包含数据包的一些说明项,比如发送者、接受者、数据类型等等;” 数据” 则是数据包的具体内容。” 标头” 的长度,固定为 18 字节。” 数据” 的长度,最短为 46 字节,最长为 1500 字节。因此,整个” 帧” 最短为 64 字节,最长为 1518 字节。如果数据很长,就必须分割成多个帧进行发送。
那么,发送者和接受者是如何标识呢?以太网规定,连入网络的所有设备都必须具有” 网卡” 接口。数据包必须是从一块网卡,传送到另一块网卡。网卡的地址,就是数据包的发送地址和接收地址,这叫做 MAC 地址。每块网卡出厂的时候,都有一个全世界独一无二的 MAC 地址,长度是 48 个二进制位,通常用 12 个十六进制数表示。前 6 个十六进制数是厂商编号,后 6 个是该厂商的网卡流水号。有了 MAC 地址,就可以定位网卡和数据包的路径了。
我们会通过 ARP 协议来获取接受方的 MAC 地址,有了 MAC 地址之后,如何把数据准确的发送给接收方呢?其实这里以太网采用了一种很” 原始” 的方式,它不是把数据包准确送到接收方,而是向本网络内所有计算机都发送,让每台计算机读取这个包的” 标头”,找到接收方的 MAC 地址,然后与自身的 MAC 地址相比较,如果两者相同,就接受这个包,做进一步处理,否则就丢弃这个包。这种发送方式就叫做 "广播"(broadcasting)。
网络层
按照以太网协议的规则我们可以依靠 MAC 地址来向外发送数据。理论上依靠 MAC 地址,你电脑的网卡就可以找到身在世界另一个角落的某台电脑的网卡了,但是这种做法有一个重大缺陷就是以太网采用广播方式发送数据包,所有成员人手一” 包”,不仅效率低,而且发送的数据只能局限在发送者所在的子网络。也就是说如果两台计算机不在同一个子网络,广播是传不过去的。这种设计是合理且必要的,因为如果互联网上每一台计算机都会收到互联网上收发的所有数据包,那是不现实的。
因此,必须找到一种方法区分哪些 MAC 地址属于同一个子网络,哪些不是。如果是同一个子网络,就采用广播方式发送,否则就采用” 路由” 方式发送。这就导致了” 网络层” 的诞生。它的作用是引进一套新的地址,使得我们能够区分不同的计算机是否属于同一个子网络。这套地址就叫做” 网络地址”,简称” 网址”。
“网络层” 出现以后,每台计算机有了两种地址,一种是 MAC 地址,另一种是网络地址。两种地址之间没有任何联系,MAC 地址是绑定在网卡上的,网络地址则是网络管理员分配的。网络地址帮助我们确定计算机所在的子网络,MAC 地址则将数据包送到该子网络中的目标网卡。因此,从逻辑上可以推断,必定是先处理网络地址,然后再处理 MAC 地址。
规定网络地址的协议,叫做 IP 协议。它所定义的地址,就被称为 IP 地址。目前,广泛采用的是 IP 协议第四版,简称 IPv4。IPv4 这个版本规定,网络地址由 32 个二进制位组成,我们通常习惯用分成四段的十进制数表示 IP 地址,从 0.0.0.0 一直到 255.255.255.255。
根据 IP 协议发送的数据,就叫做 IP 数据包。IP 数据包也分为” 标头” 和” 数据” 两个部分:” 标头” 部分主要包括版本、长度、IP 地址等信息,” 数据” 部分则是 IP 数据包的具体内容。IP 数据包的” 标头” 部分的长度为 20 到 60 字节,整个数据包的总长度最大为 65535 字节。
传输层
有了 MAC 地址和 IP 地址,我们已经可以在互联网上任意两台主机上建立通信。但问题是同一台主机上会有许多程序都需要用网络收发数据,比如 QQ 和浏览器这两个程序都需要连接互联网并收发数据,我们如何区分某个数据包到底是归哪个程序的呢?也就是说,我们还需要一个参数,表示这个数据包到底供哪个程序(进程)使用。这个参数就叫做” 端口”(port),它其实是每一个使用网卡的程序的编号。每个数据包都发到主机的特定端口,所以不同的程序就能取到自己所需要的数据。
“端口” 是 0 到 65535 之间的一个整数,正好 16 个二进制位。0 到 1023 的端口被系统占用,用户只能选用大于 1023 的端口。有了 IP 和端口我们就能实现唯一确定互联网上一个程序,进而实现网络间的程序通信。
我们必须在数据包中加入端口信息,这就需要新的协议。最简单的实现叫做 UDP 协议,它的格式几乎就是在数据前面,加上端口号。UDP 数据包,也是由” 标头” 和” 数据” 两部分组成:” 标头” 部分主要定义了发出端口和接收端口,” 数据” 部分就是具体的内容。UDP 数据包非常简单,” 标头” 部分一共只有 8 个字节,总长度不超过 65,535 字节,正好放进一个 IP 数据包。
UDP 协议的优点是比较简单,容易实现,但是缺点是可靠性较差,一旦数据包发出,无法知道对方是否收到。为了解决这个问题,提高网络可靠性,TCP 协议就诞生了。TCP 协议能够确保数据不会遗失。它的缺点是过程复杂、实现困难、消耗较多的资源。TCP 数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常 TCP 数据包的长度不会超过 IP 数据包的长度,以确保单个 TCP 数据包不必再分割。
应用层
应用程序收到” 传输层” 的数据,接下来就要对数据进行解包。由于互联网是开放架构,数据来源五花八门,必须事先规定好通信的数据格式,否则接收方根本无法获得真正发送的数据内容。” 应用层” 的作用就是规定应用程序使用的数据格式,例如我们 TCP 协议之上常见的 Email、HTTP、FTP 等协议,这些协议就组成了互联网协议的应用层。
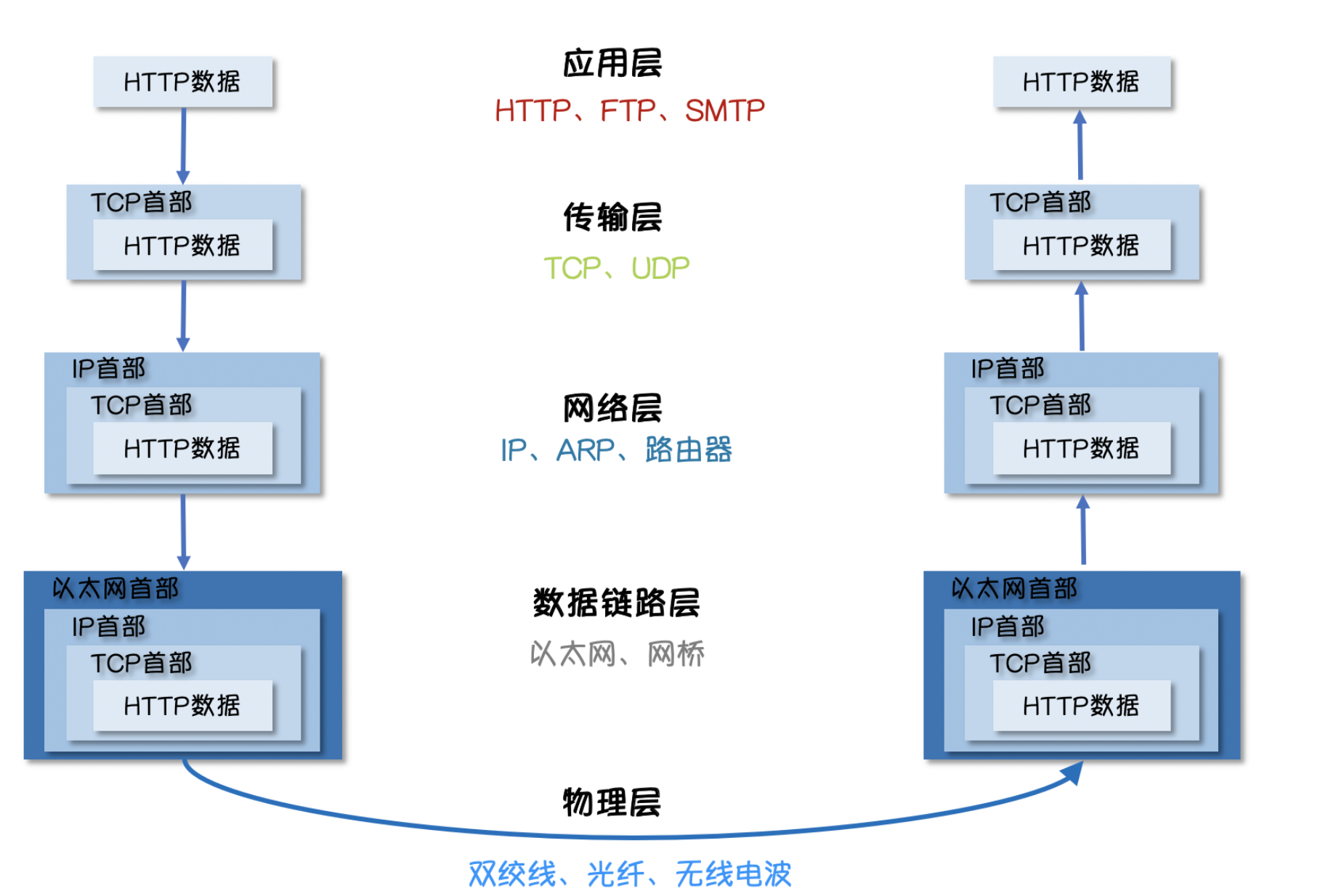
如下图所示,发送方的 HTTP 数据经过互联网的传输过程中会依次添加各层协议的标头信息,接收方收到数据包之后再依次根据协议解包得到数据。
Go web编程
HTTP 协议是 Web 工作的核心,所以要了解清楚 Web 的工作方式就需要详细的了解清楚 HTTP 是怎么样工作的。
HTTP 是一种让 Web 服务器与浏览器 (客户端) 通过 Internet 发送与接收数据的协议,它建立在 TCP 协议之上,一般采用 TCP 的 80 端口。它是一个请求、响应协议 -- 客户端发出一个请求,服务器响应这个请求。在 HTTP 中,客户端总是通过建立一个连接与发送一个 HTTP 请求来发起一个事务。服务器不能主动去与客户端联系,也不能给客户端发出一个回调连接。客户端与服务器端都可以提前中断一个连接。例如,当浏览器下载一个文件时,你可以通过点击 “停止” 键来中断文件的下载,关闭与服务器的 HTTP 连接。
HTTP 协议是无状态的,同一个客户端的这次请求和上次请求是没有对应关系,对 HTTP 服务器来说,它并不知道这两个请求是否来自同一个客户端。为了解决这个问题, Web 程序引入了 Cookie 机制来维护连接的可持续状态。
URL和DNS解析
我们浏览网页都是通过 URL 访问的,那么 URL 到底是怎么样的呢?
URL (Uniform Resource Locator) 是 “统一资源定位符” 的英文缩写,用于描述一个网络上的资源,基本格式如下
scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme 指定底层使用的协议(例如:http, https, ftp)
host HTTP 服务器的 IP 地址或者域名
port# HTTP 服务器的默认端口是 80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如 http://www.cnblogs.com:8080/
path 访问资源的路径
query-string 发送给 http 服务器的数据
anchor 锚
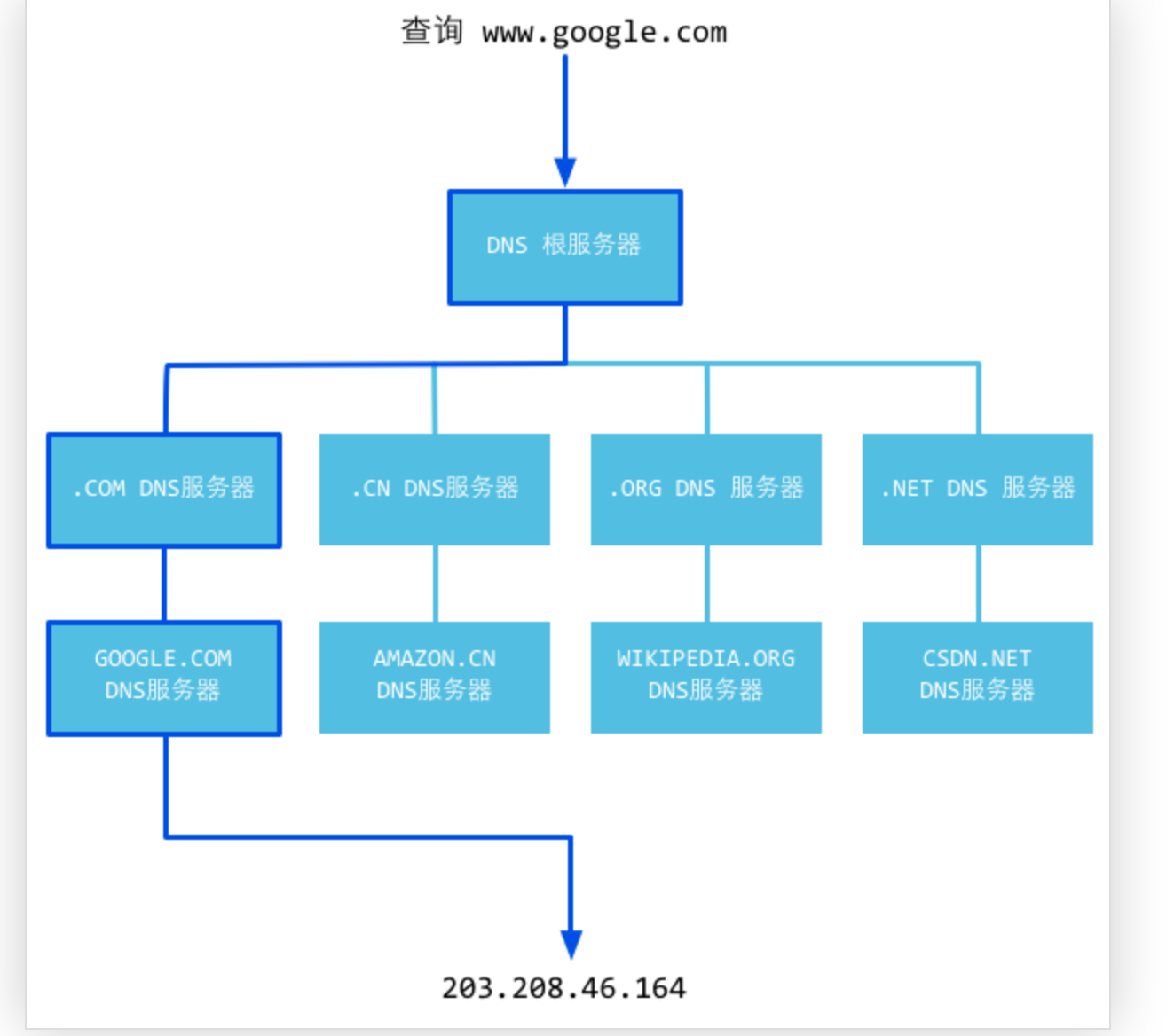
DNS解析:
HTTP 请求包(浏览器信息)
我们先来看看 Request 包的结构,Request 包分为 3 部分,第一部分叫 Request line(请求行), 第二部分叫 Request header(请求头), 第三部分是 body(主体)。header 和 body 之间有个空行,请求包的例子所示:
GET /domains/example/ HTTP/1.1 // 请求行: 请求方法 请求 URI HTTP 协议/协议版本
Host:www.iana.org // 服务端的主机名
User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 // 浏览器信息
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 // 客户端能接收的 mine
Accept-Encoding:gzip,deflate,sdch // 是否支持流压缩
Accept-Charset:UTF-8,*;q=0.5 // 客户端字符编码集
// 空行,用于分割请求头和消息体
// 消息体,请求资源参数,例如 POST 传递的参数
展示:
HTTP 响应包(服务器信息)
我们再来看看 HTTP 的 response 包,他的结构如下:
HTTP/1.1 200 OK // 状态行
Server: nginx/1.0.8 // 服务器使用的 WEB 软件名及版本
Date: Tue, 30 Oct 2022 04:14:25 GMT // 发送时间
Content-Type: text/html // 服务器发送信息的类型
Transfer-Encoding: chunked // 表示发送 HTTP 包是分段发的
Connection: keep-alive // 保持连接状态
Content-Length: 90 // 主体内容长度
// 空行 用来分割消息头和主体
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"... // 消息体
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©