go 语言常量、基本数据类型、字符串转化
[toc]
😶🌫️go语言官方编程指南:https://golang.org/#
go语言的官方文档学习笔记很全,推荐去官网学习
😶🌫️我的学习笔记:github: https://github.com/3293172751/golang-rearn
区块链技术(也称之为分布式账本技术),是一种互联网数据库技术,其特点是去中心化,公开透明,让每一个人均可参与的数据库记录
❤️💕💕关于区块链技术,可以关注我,共同学习更多的区块链技术。博客http://nsddd.top
Go 语言常量
常量是一个简单值的标识符,在程序运行时,不会被修改的量。
常量中的数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。
常量的定义格式:
const identifier [type] = value
你可以省略类型说明符 [type],因为编译器可以根据变量的值来推断其类型。
- 显式类型定义:
const b string = "abc" - 隐式类型定义:
const b = "abc"
多个相同类型的声明可以简写为:
const c_name1, c_name2 = value1, value2
以下实例演示了常量的应用:
实例
package main
import "fmt"
func main() {
const LENGTH int = 10
const WIDTH int = 5
var area int
const a, b, c = 1, false, "str" //多重赋值
area = LENGTH * WIDTH
fmt.Printf("面积为 : %d", area)
println()
println(a, b, c)
}
以上实例运行结果为:
面积为 : 50
1 false str
常量还可以用作枚举:
const (
Unknown = 0
Female = 1
Male = 2
)
数字 0、1 和 2 分别代表未知性别、女性和男性。
常量可以用len(), cap(), unsafe.Sizeof()函数计算表达式的值。常量表达式中,函数必须是内置函数,否则编译不过:
package main
import "unsafe"
const (
a = "abc"
b = len(a)
c = unsafe.Sizeof(a)
)
func main(){
println(a, b, c)
}
以上实例运行结果为:
abc 3 16
iota
iota,特殊常量,可以认为是一个可以被编译器修改的常量。
iota 在 const关键字出现时将被重置为 0(const 内部的第一行之前),const 中每新增一行常量声明将使 iota 计数一次 (iota 可理解为 const 语句块中的行索引)。
iota 可以被用作枚举值:
const (
a = iota
b = iota
c = iota
)
第一个 iota 等于 0,每当 iota 在新的一行被使用时,它的值都会自动加 1;所以 a=0, b=1, c=2 可以简写为如下形式:
const (
a = iota
b
c
)
iota 用法
package main
import "fmt"
func main() {
const (
a = iota //0
b //1
c //2
d = "ha" //独立值,iota += 1
e //"ha" iota += 1
f = 100 //iota +=1
g //100 iota +=1
h = iota //7,恢复计数
i //8
)
fmt.Println(a,b,c,d,e,f,g,h,i)
}
以上实例运行结果为:
0 1 2 ha ha 100 100 7 8
再看个有趣的的 iota 实例:
Go语言的
iota特性,如果你同时设置了两个tota,Go语言或许能发现其中的规律
package main
import "fmt"
const (
i=1<<iota ;1<<0
j=3<<iota ;3<<1
k
l
)
func main() {
fmt.Println("i=",i)
fmt.Println("j=",j)
fmt.Println("k=",k)
fmt.Println("l=",l)
}
以上实例运行结果为:
i= 1
j= 6
k= 12
l= 24
iota 表示从 0 开始自动加 1,所以 i=1<<0, j=3<<1(<< 表示左移的意思),即:i=1, j=6,这没问题,关键在 k 和 l,从输出结果看 k=3<<2,l=3<<3。
简单表述:
- i=1:左移 0 位,不变仍为 1。
- j=3:左移 1 位,变为二进制 110,即 6。
- k=3:左移 2 位,变为二进制 1100,即 12。
- l=3:左移 3 位,变为二进制 11000,即 24。
注:<<n==*(2^n)。
怎么看变量的数据类型
package main
import "fmt"
const (
i = 1<<iota
j = 3<<iota
k
l
)
func main(){
var n = 1000000
fmt.Println(i)
fmt.Println(j)
fmt.Println(l)
fmt.Println(k)
//fmt.printf()可以用来格式化输出,可以使用%d,%c
fmt.Printf("n的类型是:",n)
}
解析:
iota 表示从 0 开始自动加 1,所以 i=1<<0, j=3<<1(<< 表示左移的意思),即:i=1, j=6,这没问题,关键在 k 和 l,从输出结果看 k=3<<2,l=3<<3。
简单表述:
- i=1:左移 0 位,不变仍为 1。
- j=3:左移 1 位,变为二进制 110,即 6。
- k=3:左移 2 位,变为二进制 1100,即 12。
- l=3:左移 3 位,变为二进制 11000,即 24。
注:<<n==*(2^n)。
println:格式化输出类型
一个很常用的技巧,取两个数中间的数(a + b) / 2
如果两个数相加再除以二:就会导致可能出现溢出
所以可以选择
((b - a) >> 1) + a
使用包查看字节数:
package main
import "unsafe"
import "fmt"
func main(){
var n = 1000000
var m byte = 100
var u int64 = 999
//fmt.printf()可以用来格式化输出
fmt.Printf("n的类型是:\n",n)
fmt.Printf("u的类型%T 占用的字节数%d",u,unsafe.Sizeof(u))
fmt.Println()
fmt.Println(m)
}
注意:Golang程序中整型变量在使用中,遵守保小不保大原则,即:在程序正确运行下,尽量使用占用空间小的数据类型
- 比如年龄使用byte:范围在0~255
小数类型
| 类型 | 字节 |
|---|---|
| 单精度 float32 | 4 |
| 双精度 float64 | 8 |
很简单,不举例
注意
float64精度要更高,同时Golang没有double类型,注意
默认声明为:float64
字符类型
Golang里面没有专门的字符类型,如果要存储单个字符或者字母,一般使用byte来保存。
布尔类型
布尔类型在很多语言都很常见,在Go语言中bool类型只能是true和false
- 布尔类型占用1个字节
- 布尔类型适用于逻辑运算,一般使用为流程控制
字符串类型
字符串就是一串固定长度的字符连接起来的字符序列,go语言的字符串是由单个字节连接起来的。
package main
import(
"fmt"
)
func main(){
var address string = "我爱中国 110 hello china"
fmt.Println(address)
}
编译:
我爱中国110 hellochina
❤️ 注意:
字符串一旦赋值,就不可以修改,在Golang中字符串是不可变的
字符串的表示形式有两种,双引号和反引号(以字符串原生形式输出,包括换行和特殊字符,可以防止攻击,输出源代码)
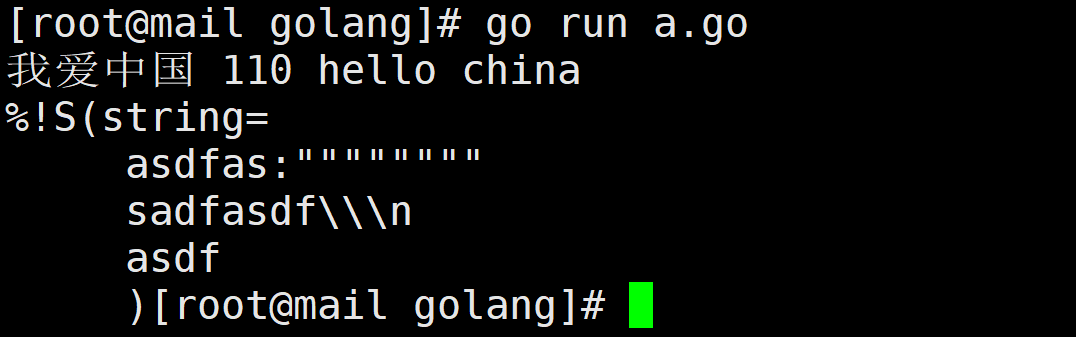
package main import( "fmt" ) func main(){ var address string = "我爱中国 110 hello china" str2 := ` asdfas:"""""""" sadfasdf\\\n asdf ` fmt.Println(address) fmt.Printf("%S",str2) }编译:
基本数据类型的相互转换
Golang和C/Java不同,Golang在不同数据类型之间赋值需要显示转化,也就是说Golang中数据类型不能==自动转化==。
Golang的类型转化类似于python
数据类型的转化可以是从小到大,也可以是从大到小
被转化的是变量存储的数据,==变量本身的数据并没有变化==
可以将int64转化为int8,编译时不会出错,只是转化的结果按溢出处理
- int8存储的数值范围[-127,+128]
var a int64 = 999999 var b int8 = int8(a) //将a的值转化为int8,此时无法存储,会溢出处理注意❤️ :溢出处理的值是不确定的
基本数据类型转string
在开发中,我们经常需要将基本数据类型转化为string类型,或者将string类型转化为基本数据类型
方法一:格式化字符串
Go 语言中使用 fmt.Sprintf 格式化字符串并赋值给新串:
💡简单的一个案例如下:
package main
import (
"fmt"
)
func main() {
// %d 表示整型数字,%s 表示字符串*
var stockcode=123
var enddate="2020-12-31"
var url="Code=%d&endDate=%s"
var target_url=fmt.Sprintf(url,stockcode,enddate) //格式化字符串
fmt.Println(target_url)
}
输出结果为:
Code=123&endDate=2020-12-31
在官方文档中:sprintf根据format参数生成格式化的字符串并返回该字符串
func Sprintf(format string,a ...interface{}) string
使用func Itoa将int类型转化为string类型
func Itoa(i int) string
Itoa是FormatInt(i, 10) 的简写。
//演示
var num int = 457
str = strconv.Ita(num) //将num的值转化为string
fmt.Printf("str type %T str = %q\n",str,str)
代码实现:
package main
import (
"fmt"
_"unsafe" //包含头文件
)
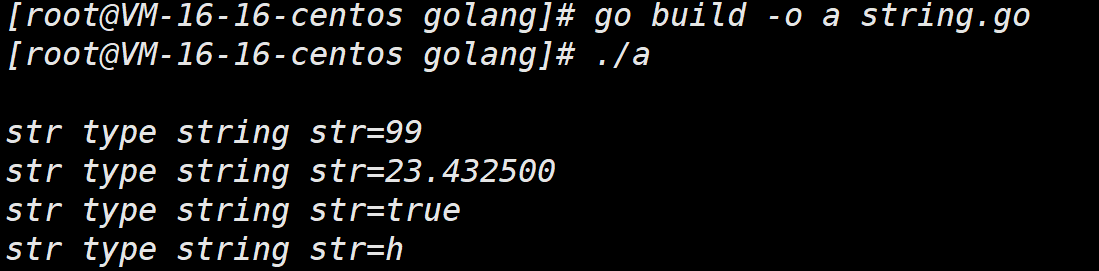
func main(){
//基本数据类型转化为string类型
var num1 int = 99
var num2 float64 = 23.4325
var b bool = true
var myChar byte = 'h'
var str string //定义一个空的字符串str
fmt.Println(str)
//使用sprintf方法来转化
str = fmt.Sprintf("%d",num1) //将Num1转化为string返回给str
fmt.Printf("str type %T str=%v\n",str,str)
str = fmt.Sprintf("%f",num2) //将Num1转化为string返回给str
fmt.Printf("str type %T str=%v\n",str,str)
str = fmt.Sprintf("%t",b) //将Num1转化为string返回给str
fmt.Printf("str type %T str=%v\n",str,str)
str = fmt.Sprintf("%c",myChar) //将Num1转化为string返回给str
fmt.Printf("str type %T str=%v\n",str,str)
}
编译:
方法二:使用strconv包的函数
import "strconv" //引入包
...
...
str = strconv.FormatInt(int64(num3),10)
fmt.Printf("str type %T str=%q\n",str,str)
//其余的一样的方法,由此可见 ,和python方法类似
string类型转化为基本数据类型
使用strconv包的函数
package main
import(
"fmt"
"strconv"
)
func main(){
var str string = "ture"
var b bool
b,_= strconv.ParseBool(str)
fmt.Printf("b type %T b=%v",b,b)
//将str2转化为int类型
var str2 string ="123141234"
var n1 int64
n1,_ = strconv.ParseInt(str2,10,64) //转化为十进制,
fmt.Printf("n1 type %T,n1=%v",n1,n1)
}
编译:
[root@mail golang]# go run a.go
b type bool b=falsen1 type int64,n1=123141234
注意:
在基本数据类型和string相互转化中,要确保string类型能转化为有效的数据,比如说转化为bool,如果不是false或者是true,Golang会转化为默认值false。
补充:Go语言的fmt包(参考官网文档)
package fmt
import "fmt"
mt包实现了类似C语言printf和scanf的格式化I/O。格式化动作('verb')源自C语言但更简单。
Printing
通用:
%v 值的默认格式表示
%+v 类似%v,但输出结构体时会添加字段名
%#v 值的Go语法表示
%T 值的类型的Go语法表示
%% 百分号
布尔值:
%t 单词true或false
整数:
%b 表示为二进制
%c 该值对应的unicode码值
%d 表示为十进制
%o 表示为八进制
%q 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示
%x 表示为十六进制,使用a-f
%X 表示为十六进制,使用A-F
%U 表示为Unicode格式:U+1234,等价于"U+%04X"
浮点数与复数的两个组分:
%b 无小数部分、二进制指数的科学计数法,如-123456p-78;参见strconv.FormatFloat
%e 科学计数法,如-1234.456e+78
%E 科学计数法,如-1234.456E+78
%f 有小数部分但无指数部分,如123.456
%F 等价于%f
%g 根据实际情况采用%e或%f格式(以获得更简洁、准确的输出)
%G 根据实际情况采用%E或%F格式(以获得更简洁、准确的输出)
字符串和[]byte:
%s 直接输出字符串或者[]byte
%q 该值对应的双引号括起来的go语法字符串字面值,必要时会采用安全的转义表示
%x 每个字节用两字符十六进制数表示(使用a-f)
%X 每个字节用两字符十六进制数表示(使用A-F)
指针:
%p 表示为十六进制,并加上前导的0x
没有%u。整数如果是无符号类型自然输出也是无符号的。类似的,也没有必要指定操作数的尺寸(int8,int64)。
宽度通过一个紧跟在百分号后面的十进制数指定,如果未指定宽度,则表示值时除必需之外不作填充。精度通过(可选的)宽度后跟点号后跟的十进制数指定。如果未指定精度,会使用默认精度;如果点号后没有跟数字,表示精度为0。举例如下:
%f: 默认宽度,默认精度
%9f 宽度9,默认精度
%.2f 默认宽度,精度2
%9.2f 宽度9,精度2
%9.f 宽度9,精度0
宽度和精度格式化控制的是Unicode码值的数量(不同于C的printf,它的这两个因数指的是字节的数量)。两者任一个或两个都可以使用''号取代,此时它们的值将被对应的参数(按''号和verb出现的顺序,即控制其值的参数会出现在要表示的值前面)控制,这个操作数必须是int类型。
对于大多数类型的值,宽度是输出字符数目的最小数量,如果必要会用空格填充。对于字符串,精度是输出字符数目的最大数量,如果必要会截断字符串。
对于整数,宽度和精度都设置输出总长度。采用精度时表示右对齐并用0填充,而宽度默认表示用空格填充。
对于浮点数,宽度设置输出总长度;精度设置小数部分长度(如果有的话),除了%g和%G,此时精度设置总的数字个数。例如,对数字123.45,格式%6.2f 输出123.45;格式%.4g输出123.5。%e和%f的默认精度是6,%g的默认精度是可以将该值区分出来需要的最小数字个数。
对复数,宽度和精度会分别用于实部和虚部,结果用小括号包裹。因此%f用于1.2+3.4i输出(1.200000+3.400000i)。
其它flag:
'+' 总是输出数值的正负号;对%q(%+q)会生成全部是ASCII字符的输出(通过转义);
' ' 对数值,正数前加空格而负数前加负号;
'-' 在输出右边填充空白而不是默认的左边(即从默认的右对齐切换为左对齐);
'#' 切换格式:
八进制数前加0(%#o),十六进制数前加0x(%#x)或0X(%#X),指针去掉前面的0x(%#p);
对%q(%#q),如果strconv.CanBackquote返回真会输出反引号括起来的未转义字符串;
对%U(%#U),输出Unicode格式后,如字符可打印,还会输出空格和单引号括起来的go字面值;
对字符串采用%x或%X时(% x或% X)会给各打印的字节之间加空格;
'0' 使用0而不是空格填充,对于数值类型会把填充的0放在正负号后面;
verb会忽略不支持的flag。例如,因为没有十进制切换模式,所以%#d和%d的输出是相同的。
对每一个类似Printf的函数,都有对应的Print型函数,该函数不接受格式字符串,就效果上等价于对每一个参数都是用verb %v。另一个变体Println型函数会在各个操作数的输出之间加空格并在最后换行。
不管verb如何,如果操作数是一个接口值,那么会使用接口内部保管的值,而不是接口,因此:
var i interface{} = 23
fmt.Printf("%v\n", i)
会输出23。
除了verb %T和%p之外;对实现了特定接口的操作数会考虑采用特殊的格式化技巧。按应用优先级如下:
如果操作数实现了Formatter接口,会调用该接口的方法。Formatter提供了格式化的控制。
如果verb %v配合flag #使用(%#v),且操作数实现了GoStringer接口,会调用该接口。
如果操作数满足如下两条任一条,对于%s、%q、%v、%x、%X五个verb,将考虑:
如果操作数实现了error接口,Error方法会用来生成字符串,随后将按给出的flag(如果有)和verb格式化。
如果操作数具有String方法,这个方法将被用来生成字符串,然后将按给出的flag(如果有)和verb格式化。
复合类型的操作数,如切片和结构体,格式化动作verb递归地应用于其每一个成员,而不是作为整体一个操作数使用。因此%q会将[]string的每一个成员括起来,%6.2f会控制浮点数组的每一个元素的格式化。
为了避免可能出现的无穷递归,如:
type X string
func (x X) String() string { return Sprintf("<%s>", x) }
应在递归之前转换值的类型:
func (x X) String() string { return Sprintf("<%s>", string(x)) }
显式指定参数索引:
在Printf、Sprintf、Fprintf三个函数中,默认的行为是对每一个格式化verb依次对应调用时成功传递进来的参数。但是,紧跟在verb之前的[n]符号表示应格式化第n个参数(索引从1开始)。同样的在'*'之前的[n]符号表示采用第n个参数的值作为宽度或精度。在处理完方括号表达式[n]后,除非另有指示,会接着处理参数n+1,n+2……(就是说移动了当前处理位置)。例如:
fmt.Sprintf("%[2]d %[1]d\n", 11, 22)
会生成"22 11",而:
fmt.Sprintf("%[3]*.[2]*[1]f", 12.0, 2, 6),
等价于:
fmt.Sprintf("%6.2f", 12.0),
会生成" 12.00"。因为显式的索引会影响随后的verb,这种符号可以通过重设索引用于多次打印同一个值:
fmt.Sprintf("%d %d %#[1]x %#x", 16, 17)
会生成"16 17 0x10 0x11"
格式化错误:
如果给某个verb提供了非法的参数,如给%d提供了一个字符串,生成的字符串会包含该问题的描述,如下所例:
错误的类型或未知的verb:%!verb(type=value)
Printf("%d", hi): %!d(string=hi)
太多参数(采用索引时会失效):%!(EXTRA type=value)
Printf("hi", "guys"): hi%!(EXTRA string=guys)
太少参数: %!verb(MISSING)
Printf("hi%d"): hi %!d(MISSING)
宽度/精度不是整数值:%!(BADWIDTH) or %!(BADPREC)
Printf("%*s", 4.5, "hi"): %!(BADWIDTH)hi
Printf("%.*s", 4.5, "hi"): %!(BADPREC)hi
没有索引指向的参数:%!(BADINDEX)
Printf("%*[2]d", 7): %!d(BADINDEX)
Printf("%.[2]d", 7): %!d(BADINDEX)
所有的错误都以字符串"%!"开始,有时会后跟单个字符(verb标识符),并以加小括弧的描述结束。
如果被print系列函数调用时,Error或String方法触发了panic,fmt包会根据panic重建错误信息,用一个字符串说明该panic经过了fmt包。例如,一个String方法调用了panic("bad"),生成的格式化信息差不多是这样的:
%!s(PANIC=bad)
%!s指示表示错误(panic)出现时的使用的verb。
Scanning
一系列类似的函数可以扫描格式化文本以生成值。
Scan、Scanf和Scanln从标准输入os.Stdin读取文本;Fscan、Fscanf、Fscanln从指定的io.Reader接口读取文本;Sscan、Sscanf、Sscanln从一个参数字符串读取文本。
Scanln、Fscanln、Sscanln会在读取到换行时停止,并要求一次提供一行所有条目;Scanf、Fscanf、Sscanf只有在格式化文本末端有换行时会读取到换行为止;其他函数会将换行视为空白。
Scanf、Fscanf、Sscanf会根据格式字符串解析参数,类似Printf。例如%x会读取一个十六进制的整数,%v会按对应值的默认格式读取。格式规则类似Printf,有如下区别:
%p 未实现
%T 未实现
%e %E %f %F %g %G 效果相同,用于读取浮点数或复数类型
%s %v 用在字符串时会读取空白分隔的一个片段
flag '#'和'+' 未实现
在无格式化verb或verb %v下扫描整数时会接受常用的进制设置前缀0(八进制)和0x(十六进制)。
宽度会在输入文本中被使用(%5s表示最多读取5个rune来生成一个字符串),但没有使用精度的语法(没有%5.2f,只有%5f)。
当使用格式字符串进行扫描时,多个连续的空白字符(除了换行符)在输出和输出中都被等价于一个空白符。在此前提下,格式字符串中的文本必须匹配输入的文本;如果不匹配扫描会中止,函数的整数返回值说明已经扫描并填写的参数个数。
在所有的扫描函数里,\r\n都被视为\n。
在所有的扫描函数里,如果一个操作数实现了Scan方法(或者说,它实现了Scanner接口),将会使用该接口为该操作数扫描文本。另外,如果如果扫描到(准备填写)的参数比提供的参数个数少,会返回一个错误。
提供的所有参数必须为指针或者实现了Scanner接口。注意:Fscan等函数可能会在返回前多读取一个rune,这导致多次调用这些函数时可能会跳过部分输入。只有在输入里各值之间没有空白时,会出现问题。如果提供给Fscan等函数的io.Reader接口实现了ReadRune方法,将使用该方法读取字符。如果该io.Reader接口还实现了UnreadRune方法,将是使用该方法保存字符,这样可以使成功执行的Fscan等函数不会丢失数据。如果要给一个没有这两个方法的io.Reader接口提供这两个方法,使用bufio.NewReader。
END 链接
✴️版权声明 © :本书所有内容遵循CC-BY-SA 3.0协议(署名-相同方式共享)©