第29节 Go语言框架三件套(Web/RPC/GORM)
❤️💕💕Go语言高级篇章,在此之前建议您先了解基础和进阶篇。Myblog:http://nsddd.top
Go语言基础篇
Go语言100篇进阶
[TOC]
ORM、GORM

ORM全称是:Object Relational Mapping(对象关系映射),其主要作用是在编程中,把面向对象的概念跟数据库中表的概念对应起来。
举例来说就是,我定义一个对象,那就对应着一张表,这个对象的实例,就对应着表中的一条记录。
GORM:是Golang语言中一款性能极好的ORM库,对开发人员相对是比较友好的。
GROM
GORM特性
- 全功能 ORM
- 关联 (Has One,Has Many,Belongs To,Many To Many,多态,单表继承)
- Create,Save,Update,Delete,Find 中钩子方法
- 支持
Preload、Joins的预加载 - 事务,嵌套事务,Save Point,Rollback To Saved Point
- Context、预编译模式、DryRun 模式
- 批量插入,FindInBatches,Find/Create with Map,使用 SQL 表达式、Context Valuer 进行 CRUD
- SQL 构建器,Upsert,数据库锁,Optimizer/Index/Comment Hint,命名参数,子查询
- 复合主键,索引,约束
- Auto Migration
- 自定义 Logger
- 灵活的可扩展插件 API:Database Resolver(多数据库,读写分离)、Prometheus…
- 每个特性都经过了测试的重重考验
- 开发者友好
驱动方式链接
GORM 是通过驱动的方式来链接数据库的,目前支持 Mysql、SQLSever、PostgreSQL、SQLite。如果需要链接其他类型的数据库,可以 复用/自行 开发驱动。
- 驱动,是指软件驱动程序。是一种中间件,它能够将应用程序与硬件或其他系统之间的信息进行转换。在数据库领域中,驱动程序就是一种软件,它能够将应用程序与数据库之间的信息进行转换。
- 驱动程序通常提供一组标准的数据库连接接口。这些接口包括连接数据库、执行 SQL 语句、获取结果集等。应用程序可以使用这些接口与数据库进行交互。
在 GORM 中,驱动程序是将 Go 语言与数据库之间的信息进行转换的软件。 GORM 库使用驱动程序来连接数据库,并使用驱动程序提供的接口来进行数据库操作。这样,GORM 库就不用关心数据库是哪种数据库,只要有驱动程序就可以连接数据库。
驱动是一种软件,它能够将 Go 语言与数据库之间的信息进行转换。驱动通过一组标准的数据库连接接口来提供连接数据库的功能。
GORM 的设计原则是对数据库访问进行封装,而不是对 SQL 语句进行封装。这样可以让开发人员专注于业务逻辑,而不用关心数据库的细节。
以驱动的方式链接数据库的好处是:
- 使用驱动可以支持多种数据库,而不用对 GORM 进行修改。
- 使用驱动可以更好地支持数据库的新特性。
- 使用驱动可以更好地进行数据库性能优化。
DSN
[[DSN]] 是 Data Source Name 的缩写,是一种数据库连接字符串,它提供了连接数据库所需的所有信息。
DSN 的格式通常包括数据库类型、数据库名称、用户名、密码和连接地址等信息。
例如对于 mysql 数据库来说,DSN 格式如下:
user:password@tcp(host:port)/dbname
其中:
user: 数据库用户名password: 数据库密码host: 数据库地址port: 数据库端口dbname: 数据库名称
DSN 字符串的格式可能因数据库类型而异。
使用DSN字符串连接数据库是一种常用的方式,因为它简化了连接数据库的过程,并且使用DSN字符串连接的数据库驱动程序通常支持多种数据库类型,这样就不用写多个连接数据库的函数了。
安装和简单实用
GORM安装:
go get -u gorm.io/gorm
go get -u gorm.io/driver/sqlite
Quick Start:
package main
import (
"gorm.io/gorm"
"gorm.io/driver/sqlite"
)
// 创建数据模型
type Product struct {
gorm.Model
Code string
Price uint
}
func main() {
db, err := gorm.Open(sqlite.Open("test.db"), &gorm.Config{})
if err != nil {
panic("failed to connect database")
}
// 迁移 schema
db.AutoMigrate(&Product{})
// Create
db.Create(&Product{Code: "D42", Price: 100})
// Read
var product Product
db.First(&product, 1) // 根据整型主键查找
db.First(&product, "code = ?", "D42") // 查找 code 字段值为 D42 的记录
// Update - 将 product 的 price 更新为 200
db.Model(&product).Update("Price", 200)
// Update - 更新多个字段
db.Model(&product).Updates(Product{Price: 200, Code: "F42"}) // 仅更新非零值字段
db.Model(&product).Updates(map[string]interface{}{"Price": 200, "Code": "F42"})
// Delete - 删除 product
db.Delete(&product, 1)
}
Mysql 的💡简单的一个案例如下:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
// 定义数据模型
type Product struct {
ID uint `gorm:"primary_key"`
Name string `gorm:"size:255"`
Price uint
}
func main() {
// 建立数据库连接
db, err := gorm.Open("mysql", "root:password@/dbname?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic("连接数据库失败")
}
defer db.Close()
// 自动迁移数据库结构
db.AutoMigrate(&Product{})
// 创建一条数据
db.Create(&Product{Name: "面包", Price: 3})
// 查询所有数据
var products []Product
db.Find(&products)
fmt.Println("所有产品:", products)
// 更新一条数据
db.Model(&Product{}).Where("name = ?", "面包").Update("price", 4)
// 删除一条数据
db.Where("name = ?", "面包").Delete(&Product{})
}
📜 对上面的解释:
- 在 main 函数中,我们通过调用 gorm.Open("mysql", "root:password@/dbname?charset=utf8&parseTime=True&loc=Local") 来建立数据库连接。
- 我们使用 db.AutoMigrate(&Product{}) 来自动迁移数据库结构,即自动根据 Product 结构体创建数据表。
- 我们使用 db.Create(&Product{Name: "面包", Price: 3}) 来创建一条数据。
- 使用 db.Find(&products) 来查询所有数据并将其存入 products 变量中。
- 我们使用 db.Model(&Product{}).Where("name = ?", "面包").Update("price", 4) 来更新名称为 "面包" 的产品的价格。
- 我们使用 db.Where("name = ?", "面包").Delete(&Product{}) 来删除名称为 "面包" 的产品。
- 最后,通过 defer db.Close() 关闭数据库连接。
更细节的操作可以参考:GORM 指南 | GORM - The fantastic ORM library for Golang, aims to be developer friendly.
可以使用gorm.Open()函数打开数据库连接。 例如:
db, err := gorm.Open("mysql", "user:password@/dbname?charset=utf8&parseTime=True&loc=Local")
这里是一些基本的GORM用法,尝试使用它来 创建、读取、更新和删除 数据库记录。
// create
db.Create(&Product{Code: "L1212", Price: 1000})
// read
var product Product
db.First(&product, 1) // find product with id 1
// update
db.Model(&product).Update("Price", 2000)
// delete
db.Delete(&product)
解决数据冲突
在 GORM 中,使用 OnConflict 方法可以解决数据冲突问题。这个方法可以让你指定在冲突时应该采取的操作。
一般来说,在执行插入操作时可能会因为主键重复而导致数据冲突。使用 OnConflict 方法可以解决这个问题。
💡简单的一个案例如下:
db.Save(&Product{Name: "面包", Price: 3}).OnConflict("(name) DO UPDATE SET price = excluded.price")
这行代码表示 如果 name 列重复时,将执行更新操作来更新 price 列。
还可以使用 OnConflict("(name) DO NOTHING") 来让重复的数据不做任何操作。
OnConflict 方法非常有用,因为它可以帮助你解决数据冲突问题,并让你更好地控制你的数据库。
使用默认值
GORM 支持在数据库中设置默认值。这可以通过在结构体中使用 "default" 标签来实现。
type Product struct {
gorm.Model
Name string
Price int `gorm:"default:0"`
}
这样的话,在创建或更新数据时,如果没有指定 Price 列的值,那么会自动将其设置为 0。
默认值还可以使用SQL表达式和函数来进行设置。
例如,如果你想让 created_at 列默认值为当前时间,你可以这样定义:
type Product struct {
gorm.Model
Name string
Price int `gorm:"default:0"`
CreatedAt time.Time `gorm:"default:now()"`
}
设置默认值是非常有用的,它可以帮助你简化代码并减少错误。
First 使用详细
First 是 GORM 中查询数据的一种方法,它可以返回第一条符合条件的数据。使用 First 方法时需要传递一个参数,这个参数可以是模型结构体的指针或接口。

例如,如果你想查询第一条名称为 "Apple" 的产品数据,你可以这样写:
var product Product
db.First(&product, "name = ?", "Apple")
这里的参数是一个模型结构体的指针,第二个参数是查询条件,第三个参数是条件的值。
也可以使用链式查询来实现这个操作,如下:
var product Product
db.Where("name = ?", "Apple").First(&product)
⚠️ 在链式调用的时候,需要注意~!
使用时需要注意,如果查询不到符合条件的数据,First 方法将不会返回错误,而是返回一个空结构体。所以需要在使用时自己判断是否查询到数据。
var product Product
err := db.Where("name = ?", "Apple").First(&product).Error
if err != nil {
fmt.Println(err)
}
如果想要在查询不到数据时返回错误,可以使用 FirstOrInit 和 FirstOrCreate 方法,它们在查询不到数据时会返回错误。
在使用 First 方法时, 如果传入的结构体中有组合索引,但没有使用 Where 函数来限制组合索引的值会触发。
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
type User struct {
ID int
Name string
}
func main() {
db, err := gorm.Open("mysql", "root:password@tcp(127.0.0.1:3306)/test?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
defer db.Close()
// 查询第一条ID为1的用户
var user User
db.First(&user, 1)
fmt.Println(user)
}
这里我们使用了GORM的First方法来查询第一条ID为1的用户。需要注意的是,如果查询不到符合条件的记录,First方法会返回ecordNotFound错误。
使用时需要注意,如果传递的参数是结构体指针,gorm会将查询结果赋值到结构体上,而传递结构体则不会有赋值操作。
另外,在使用First方法查询时,如果没有符合条件的记录,返回的错误是RecordNotFound,需要在业务代码中特判这个错误。
Find
Find 方法用来查询符合条件的记录,并以切片的形式返回。
下面是一个示例代码,假设有一个名为users的表,你需要查询所有年龄大于30岁的用户:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
type User struct {
ID int
Name string
Age int
}
func main() {
db, err := gorm.Open("mysql", "root:password@/dbname?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic("failed to connect database")
}
defer db.Close()
var users []User
db.Where("age > ?", 30).Find(&users)
fmt.Println(users)
}
在上面的代码中,我们首先打开了一个数据库链接,然后定义了一个User结构体,用来存储查询到的用户信息。
接着我们使用Where方法限定查询条件,并调用Find方法查询数据。Find方法的第一个参数是一个结构体切片的指针,用来存储查询到的记录。
最后我们打印出查询到的用户信息。
⚠️ 注意:如果没有符合条件的记录,Find方法会返回一个空的切片。
First 和 Find
First方法和Find方法都是用来查询记录的,但是它们的用法和返回结果有所不同。
First方法会查询并返回第一条符合条件的记录。它的返回值是一个结构体,如果没有符合条件的记录,会返回RecordNotFound错误。
Find方法会查询所有符合条件的记录,并将它们以切片的形式返回。它的返回值是一个结构体切片,如果没有符合条件的记录,会返回一个空的切片。
举个例子,如果你要查询一个表中的第一条记录,可以使用First方法;如果你要查询一个表中所有符合条件的记录,可以使用Find方法。
总的来说,如果你只需要查询一条记录,使用First方法会更加高效,因为它只会查询一条记录;如果你需要查询多条记录,使用Find方法会更加方便。
更新数据
Gorm 提供了 Save 、 Updates 和 Update 方法用来更新数据。
Save方法更新所有字段,如果没有主键或者自增字段会新增一条记录。Updates方法用来更新指定字段。Update方法用来更新指定字段并且指定更新条件。
下面是一个示例代码,假设有一个名为users的表,你需要更新id为1的用户的姓名为 "John Doe"
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
type User struct {
ID int
Name string
Age int
}
func main() {
db, err := gorm.Open("mysql", "root:password@/dbname?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic("failed to connect database")
}
defer db.Close()
var user User
db.First(&user, 1) // find user with id 1
user.Name = "John Doe"
db.Save(&user)
fmt.Println(user)
}
在上面的代码中,我们首先打开了一个数据库链接,然后定义了一个User结构体,用来存储查询到的用户信息。
接着我们使用First方法查询id 为1的用户,并更新用户的姓名。
最后我们使用Save方法更新数据。
如果只需要更新一些字段,可以使用 Updates 方法,例如:
db.Model(&user).Updates(map[string]interface{}{"name": "John Doe", "age": 25})
Gorm 更新数据有两种方式:
- 使用 Update 方法:
db.Model(&user).Update("name", "new_name")
这种方式可以对指定字段进行更新,而不会影响其他字段的值。
- 使用 Save 方法:
user.Name = "new_name"
db.Save(&user)
这种方式会更新整个结构体。
在使用这些方法之前,需要确保记录已经在数据库中存在。如果需要在更新之前判断记录是否存在,可以使用 FirstOrCreate 方法。
注意,在使用 Save 方法时,如果结构体中有没有被赋值的字段,那么这些字段可能会被赋上空值,所以需要特别小心。
顺便提一下,在更新数据时,Gorm 会自动跟踪更新时间,如果更新时间字段名为 updated_at,则自动更新,如果需要自定义字段名,需要手动设置。
删除
Gorm 提供了 Delete 方法来删除数据。
使用 Delete 方法可以删除一条记录,方法的参数是要删除的记录的指针。
db.Delete(&user)
这个方法会将这条记录从数据库中删除,删除之后该记录就不再是有效的。
如果要删除多条记录,可以使用 Where 方法限制删除范围。
db.Where("age > ?", 20).Delete(User{})
这个方法会删除年龄大于20岁的所有用户。
注意,在删除数据时,Gorm 不会自动跟踪删除时间,如果需要记录删除时间,需要手动设置。
物理删除和软删除
物理删除和软删除是 Gorm 提供的两种不同的删除方式。
- 物理删除就是直接从数据库中删除记录,不管有没有其他业务逻辑的依赖,这种方式删除的数据不可恢复,需要谨慎使用。
- 软删除是通过在数据表中添加一个删除标记来标记记录被删除,这种方式删除的数据可以恢复,适用于不需要永久删除数据的场景。
Gorm 提供了一些辅助方法来支持软删除,比如 DeletedAt 字段,在使用 Delete 方法删除数据时会自动设置这个字段,可以通过 Unscoped 方法来忽略这个字段来进行物理删除。
Gorm默认不支持软删除,需要手动支持。Gorm 提供了 gorm.DeletedAt 用于帮助用户实现软删除
package main
import (
"fmt"
"time"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/sqlite"
)
type User struct {
ID uint `gorm:"primary_key"`
Name string
Age uint
DeletedAt *time.Time `sql:"index"` // 定义软删除字段
}
func main() {
db, err := gorm.Open("sqlite3", "test.db")
if err != nil {
fmt.Println(err)
return
}
defer db.Close()
// 开启软删除
db.AutoMigrate(&User{}).Delete(&User{}, "deleted_at is not null")
db.Callback().Delete().Add("gorm:delete", func(scope *gorm.Scope) {
if !scope.HasError() {
var extraOption string
if str, ok := scope.Get("gorm:delete_option"); ok {
extraOption = fmt.Sprint(str)
}
deletedOnField, hasDeletedOnField := scope.FieldByName("DeletedAt")
if !scope.Search.Unscoped && hasDeletedOnField {
scope.Raw(fmt.Sprintf(
"UPDATE %v SET %v=%v%v%v",
scope.QuotedTableName(),
scope.Quote(deletedOnField.DBName),
scope.AddToVars(time.Now()),
addExtraSpaceIfExist(scope.CombinedConditionSql()),
addExtraSpaceIfExist(extraOption),
)).Exec()
} else {
scope.Raw(fmt.Sprintf(
"DELETE FROM %v%v%v",
scope.QuotedTableName(),
addExtraSpaceIfExist(scope.CombinedConditionSql()),
addExtraSpaceIfExist(extraOption),
)).Exec()
}
}
})
// 创建用户
user := User{Name: "John", Age: 20}
db.Create(&user)
// 软删除用户
db.Delete(&user)
// 查询已被软删除的用户
var deletedUser User
db.Unscoped().First(&deletedUser, "name = ?", "John")
fmt.Printf("Deleted user: %+v\n", deletedUser)
}
事务
Gorm支持多种方式来管理数据库的事务。一种常用的方式是使用db.Begin()来开启一个事务,然后使用tx.Commit()或tx.Rollback()来结束事务。
在GORM中,事务是通过DB对象的Begin()方法来开始一个事务,该方法返回一个TX对象。然后你可以在TX对象上执行数据库操作,最后调用Commit()或Rollback()来结束事务。
tx := db.Begin()
// 注意在后面从这里开始,你应该使用 `tx` 而不是 `db`
defer func() {
if r := recover(); r != nil {
tx.Rollback()
}
}()
if err := tx.Error; err != nil {
panic(err)
}
// 执行数据库操作
if err := tx.Commit().Error; err != nil {
panic(err)
}
或者 使用 db.Transaction(func(tx *gorm.DB) error{}) 来进行事务操作
如果你需要在一组数据库操作之间开始和结束事务,可以使用db.Transaction(func(tx *gorm.DB) error{}) 来进行事务操作
tansaction 方法用于自动提交事务,避免用户漏写 Commit、Rollbcak
err := db.Transaction(func(tx *gorm.DB) error {
// 执行数据库操作
return nil
})
注意:如果返回值为nil,事务会提交,如果返回值非nil,事务会回滚。
GORM Hook
GORM Hook是GORM中的一种事件钩子机制,它允许在对数据库进行操作时,在特定的时间点执行额外的代码。
GORM Hook提供了多种事件类型,如创建、更新、查询和删除等。
可以使用db.Callback()来定义Hook,如下所示:
package main
import (
"fmt"
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/sqlite"
)
type Product struct {
gorm.Model
Code string
Price uint
}
func main() {
db, err := gorm.Open("sqlite3", "test.db")
if err != nil {
panic("failed to connect database")
}
defer db.Close()
db.AutoMigrate(&Product{})
// 定义钩子
db.Callback().Create().Before("gorm:begin_transaction").
Register("gorm:before_create", func(scope *gorm.Scope) {
fmt.Println("在创建之前执行的代码")
})
db.Callback().Create().After("gorm:commit_or_rollback_transaction").
Register("gorm:after_create", func(scope *gorm.Scope) {
fmt.Println("在创建之后执行的代码")
})
// 创建一个Product实例并保存
db.Create(&Product{Code: "L1212", Price: 1000})
}
上面这个例子,当数据库创建操作时会触发gorm:before_create事件,并执行函数中的代码
可以使用如下的事件类型:
Before/After("gorm:create")Before/After("gorm:query")Before/After("gorm:update")Before/After("gorm:delete")
通过这些事件类型,可以在对数据库进行操作时,对数据进行预处理或后处理,也可以在数据库操作失败时进行错误处理。
Gorm 性能提高
GORM是一个ORM库,它会在运行时执行很多操作,因此其运行性能可能不如直接使用原生SQL。但是,还是有一些方法可以提高GORM的性能。
- 使用缓存: GORM支持对数据库的缓存,如果你的应用程序需要频繁读取数据库中的同一数据,可以考虑使用缓存来提高性能。
- 尽量减少查询次数: GORM在查询数据库时会执行很多操作,如果你可以通过减少查询次数来提高性能,就应该尽量这样做。
- 尽量减少使用高级功能: GORM支持很多高级功能,如果你不需要这些功能,可以考虑不使用它们,以提高性能。
- 尽量使用批量操作: GORM支持对多个对象批量进行操作,如果你需要对多个对象进行相同的操作,可以考虑使用批量操作来提高性能。
- 数据库连接池: GORM默认使用数据库连接池来管理数据库连接,但是默认的连接池大小可能不够,可以通过调整连接池大小来提高性能。
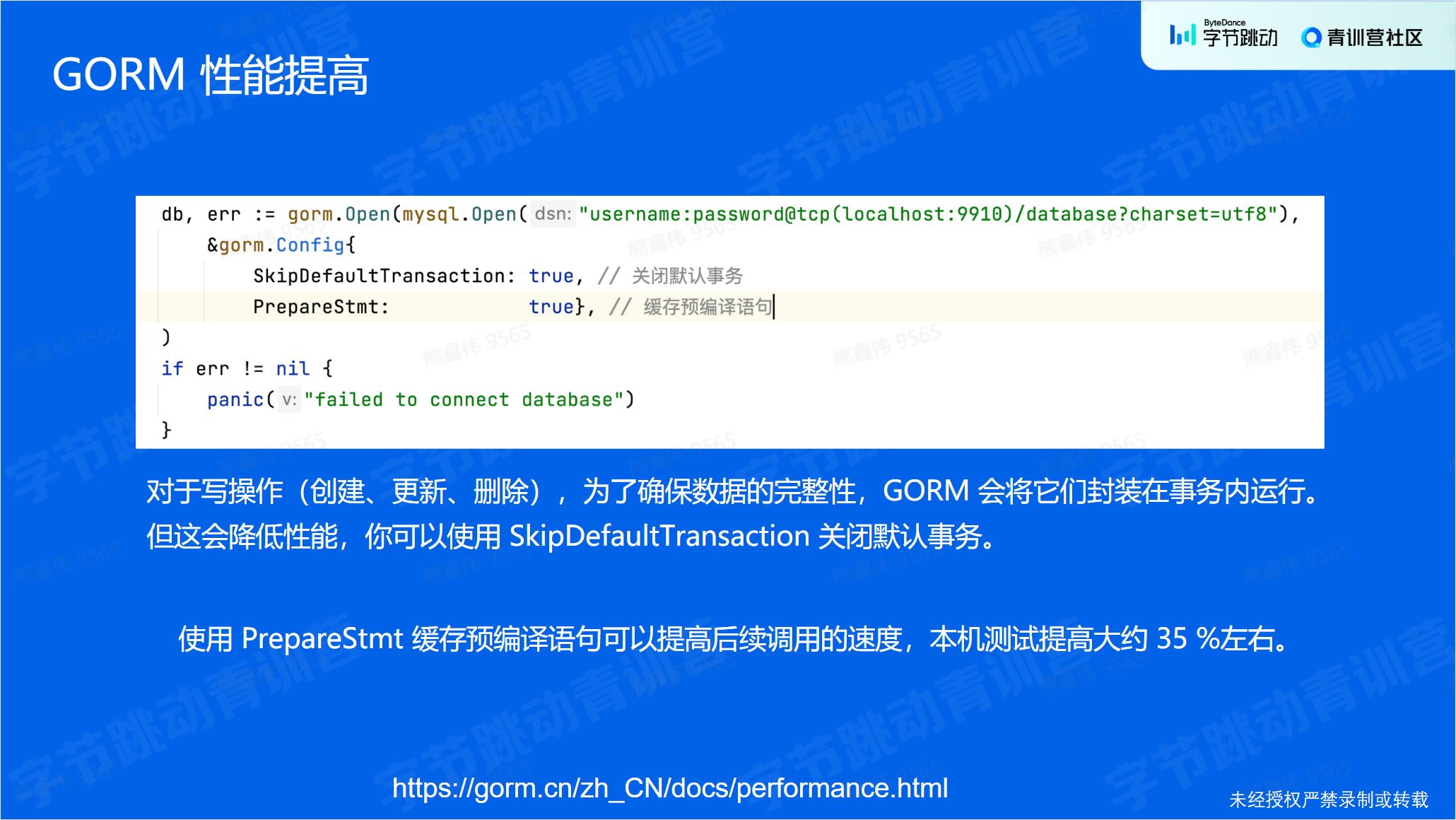
缓存预编译
预编译是一种将 SQL 语句编译为数据库可以识别的语句的过程。这种编译过程可以提高查询性能,因为数据库不需要在每次执行查询时都重新编译 SQL 语句。
GORM 中可以使用预编译语句来提高查询性能。使用预编译语句的方法是将 SQL 语句传递给 gorm.DB.Exec 或 gorm.DB.Query,并将需要传递给 SQL 语句的参数作为第二个参数传递。
💡简单的一个案例如下:
db.Exec("INSERT INTO users (name, age) VALUES (?, ?)", "John Doe", 30)
其中,第一个参数是预编译的 SQL 语句,第二个参数是要传递给 SQL 语句的参数。
缓存预编译是一种优化查询性能的方法,它可以将预编译过的 SQL 语句存储在缓存中,以便在需要执行相同的查询时可以重用已编译的语句。这可以减少数据库编译 SQL 的开销,提高性能。
db, err := gorm.Open("mysql", "user:password@/dbname?charset=utf8&parseTime=True&loc=Local&strict=true&cache=true")
其中,strict=true 参数告诉 GORM 在每次操作时都启用事务,cache=true 参数告诉 GORM 缓存预编译语句。
使用缓存预编译语句可以显著提高查询性能,特别是对于执行相同的查询的情况。
关闭默认事务
GORM 默认在每次数据库操作时都会启用事务,但是有时候我们不需要这样。
在 GORM 中关闭默认事务可以使用 gorm.Open 方法打开数据库连接时的参数。
db, err := gorm.Open("mysql", "user:password@/dbname?charset=utf8&parseTime=True&loc=Local&autocommit=true")
其中,autocommit=true 参数告诉 GORM 在每次操作时不启用事务。如果不需要事务,这样做可以提高性能。
注意:关闭事务后需要自己手动管理事务,如果需要事务支持,请不要关闭默认事务。
GORM生态
| 扩展名称 | 描述 | GitHub地址 |
|---|---|---|
| GORM 代码生成工具 | 可以根据数据库表结构自动生成 Go 代码,帮助使用 GORM 的用户更快速地开发 | https://github.com/go-gorm/gen |
| GORM 分片库方案 | 对 GORM 进行的分片库扩展,可以帮助用户管理分片数据库 | https://github.com/go-gorm/sharding |
| GORM 手动索引 | 帮助用户在 GORM 中手动创建索引 | https://github.com/go-gorm/hints |
| GORM 乐观锁 | 对 GORM 进行的乐观锁扩展,可以帮助用户处理并发冲突 | https://github.com/go-gorm/optimisticlock |
| GORM 读写分离 | 对 GORM 进行的读写分离扩展,可以帮助用户优化数据库性能 | https://github.com/go-gorm/dbresolver |
| GORM OpenTelemetry 扩展 | 对 GORM 进行的 OpenTelemetry 扩展,可以帮助用户对 GORM 的性能进行监控和追踪 | https://github.com/go-gorm/opentelemetry |
更多用法:https://gorm.cn
Kitex
- [x] github地址
Kitex是字节内部的Golang微服务PRC框架。
Kitex是一个高性能的开源网络库,它具有高性能、低延迟和高可靠性特点。它支持多种协议,如TCP、UDP、HTTP和RPC等,可以用于构建分布式系统、微服务和云计算等应用。 Kitex的主要用途是在应用程序中提供高性能的网络通信支持,并帮助开发人员更轻松地实现分布式应用程序和微服务。
Kitex 目前对 Windows 的支持不完善,如果本地开发环境是 windows 的话需要用到 虚拟机或者是 WSL2。
安装代码生成工具:
go install github.com/cloudwego/kitex/tool/cmd/kitex@latest
go install github.com/cloudwego/thriftgo@latest
验证:
kitex -version
定义 IDL
IDL (Interface Definition Language) 是指接口定义语言,是用于描述远程过程调用(RPC)或对象请求代理(ORP)接口的语言。 IDL 中定义了远程对象的接口,其中包括方法名称、参数类型和返回值类型等信息。这些信息可以用于生成代码来实现远程调用。常见的 IDL 标准有 CORBA 和 Microsoft COM/DCOM。
生成代码
使用下面的命令生成代码:
kitex -module example -service example echo.thrift
RPC(Remote Procedure Call Protocol)远程过程调用协议。一个通俗的描述是:客户端在不知道调用细节的情况下,调用存在于远程计算机上的某个对象,就像调用本地应用程序中的对象一样。比较正式的描述是:一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
// 使用IDL定义服务与接口
/*
如果我们要进行PRC,就需要知道对方的接口是什么,需要传什么参数,同时也需要知道返回值时什么样的,这个时候,就需要通过IDL来约定双方的协议,就像在写代码的时候需要调用某个函数,我们需要知道函数签名一样。
*/
// Thrift: https://thrift.apache.org/docs/idl
// Proto3: https://developers.google.com/protocol-buffers/docs/proto3
namespace go api
struct Request {
1: string message
}
struct Response {
1: string message
}
service Echo {
Response echo(1: Request req)
}
文件说明:
- build.sh:构建脚本
- kitex_gen:IDL内容相关的生成代码,主要是基础的Server/Client代码
- main.go:程序入口
- handler.go:用户在该文件里实现IDLservice定义的方法
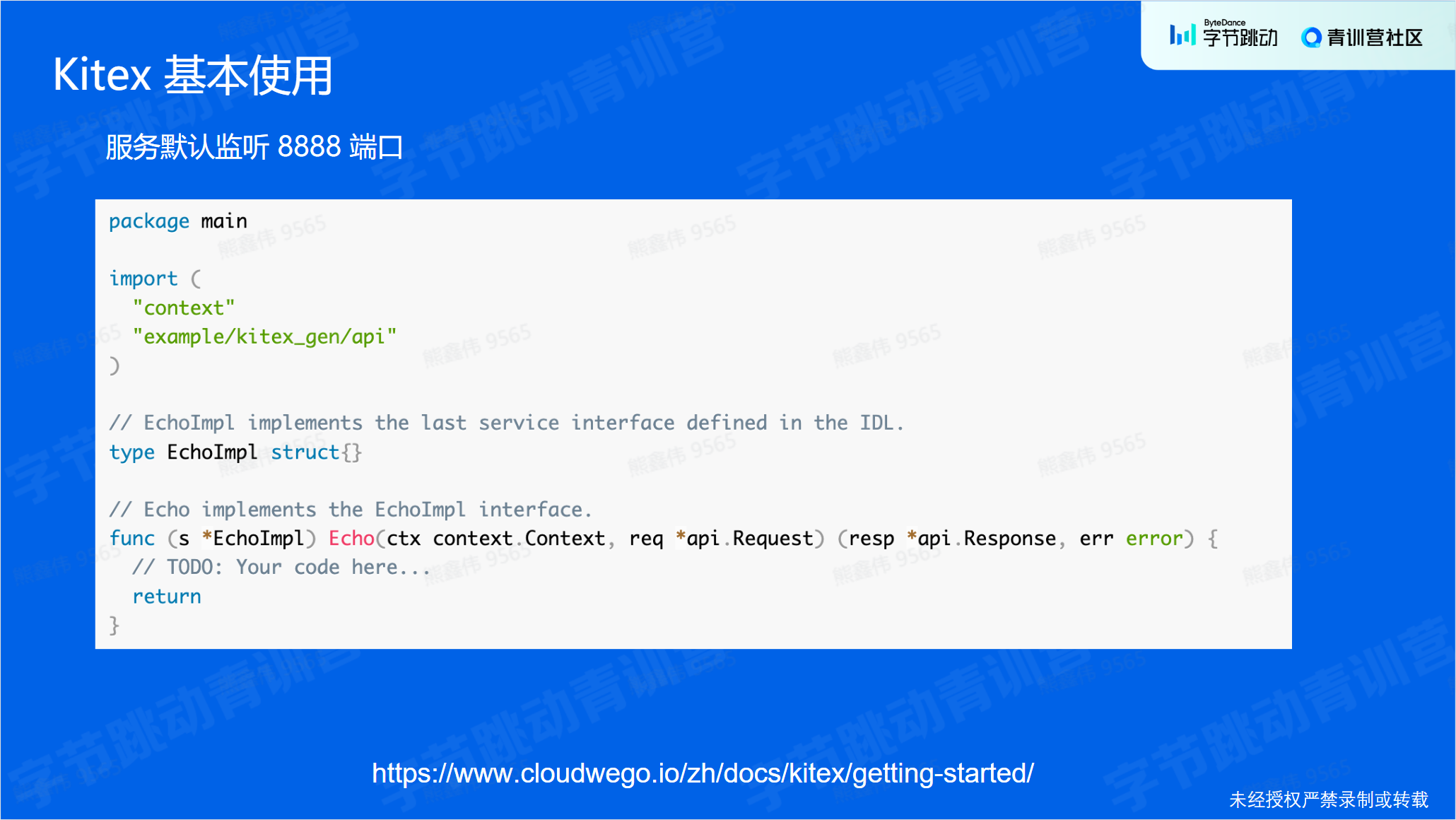
服务默认监听8888端口;
Kitex Client发起请求:
- 创建Client
- 发起请求
Kitex服务注册与发现:
目前Kitex的服务注册与发现已经对接了主流的服务注册与发现中心,如ETCD,Nacos等;
Kitex生态:
详见:https://www.cloudwego.io/zh/docs/kitex/
发起请求:

Kitex 服务注册与发现
目前的 Kitex 的服务注册与发现已经对接了主流的服务注册与发现中心,如 ETCD 、Nacos


生态

Hertz
Hertz 是字节内部的 HTTP 框架。
Hertz 是字节跳动服务框架团队研发的超大规模的企业级微服务 HTTP 框架,具有 高易用性、易扩展、低时延 等特点。在经过了字节跳动内部一年多的使用和迭代,如今已在 CloudWeGo 正式开源。目前,Hertz 已经成为了字节跳动内部最大的 HTTP 框架,线上接入的服务数量超过 1 万,峰值 QPS 超过 4 千万。除了各个业务线的同学使用外,也服务于内部很多基础组件,如: 函数计算平台 FaaS、压测平台、各类网关、Service Mesh 控制面等,均收到不错的使用反馈。在如此大规模的场景下,Hertz 拥有极强的稳定性和性能,在内部实践中某些典型服务,如框架占比较高的服务、网关等服务,迁移 Hertz 后相比 Gin 框架,资源使用显著减少,CPU 使用率随流量大小降低 30%-60%,时延也有明显降低。
Hertz 坚持内外维护一套代码,为开源使用提供了强有力的保障。通过开源, Hertz 也将丰富云原生的 Golang 中间件体系,完善 CloudWeGo 生态矩阵,为更多开发者和企业搭建云原生化的大规模分布式系统,提供一种现代的、资源高效的的技术方案。
项目源码
最初,字节跳动内部的 HTTP 框架是对 Gin 框架的封装,具备不错的易用性、生态完善等优点。随着内部业务的不断发展,高性能、多场景的需求日渐强烈。而 Gin 是对 Golang 原生 net/http 进行的二次开发,在按需扩展和性能优化上受到很大局限。因此,为了满足业务需求,更好的服务各大业务线,2020 年初,字节跳动服务框架团队经过内部使用场景和外部主流开源 HTTP 框架 Fasthttp、Gin、Echo 的调研后,开始基于自研网络库 Netpoll 开发内部框架 Hertz,让 Hertz 在面对企业级需求时,有更好的性能及稳定性表现,也能够满足业务发展和应对不断演进的技术需求。
架构设计
Hertz 设计之初调研了大量业界优秀的 HTTP 框架,同时参考了近年来内部实践中积累的经验。为了保证框架整体上满足:1. 极致性能优化的可能性;2. 面对未来不可控需求的扩展能力, Hertz 采用了 4 层分层设计,保证各个层级功能内聚,同时通过层级之间的接口达到灵活扩展的目标。整体架构图如图 1 所示。
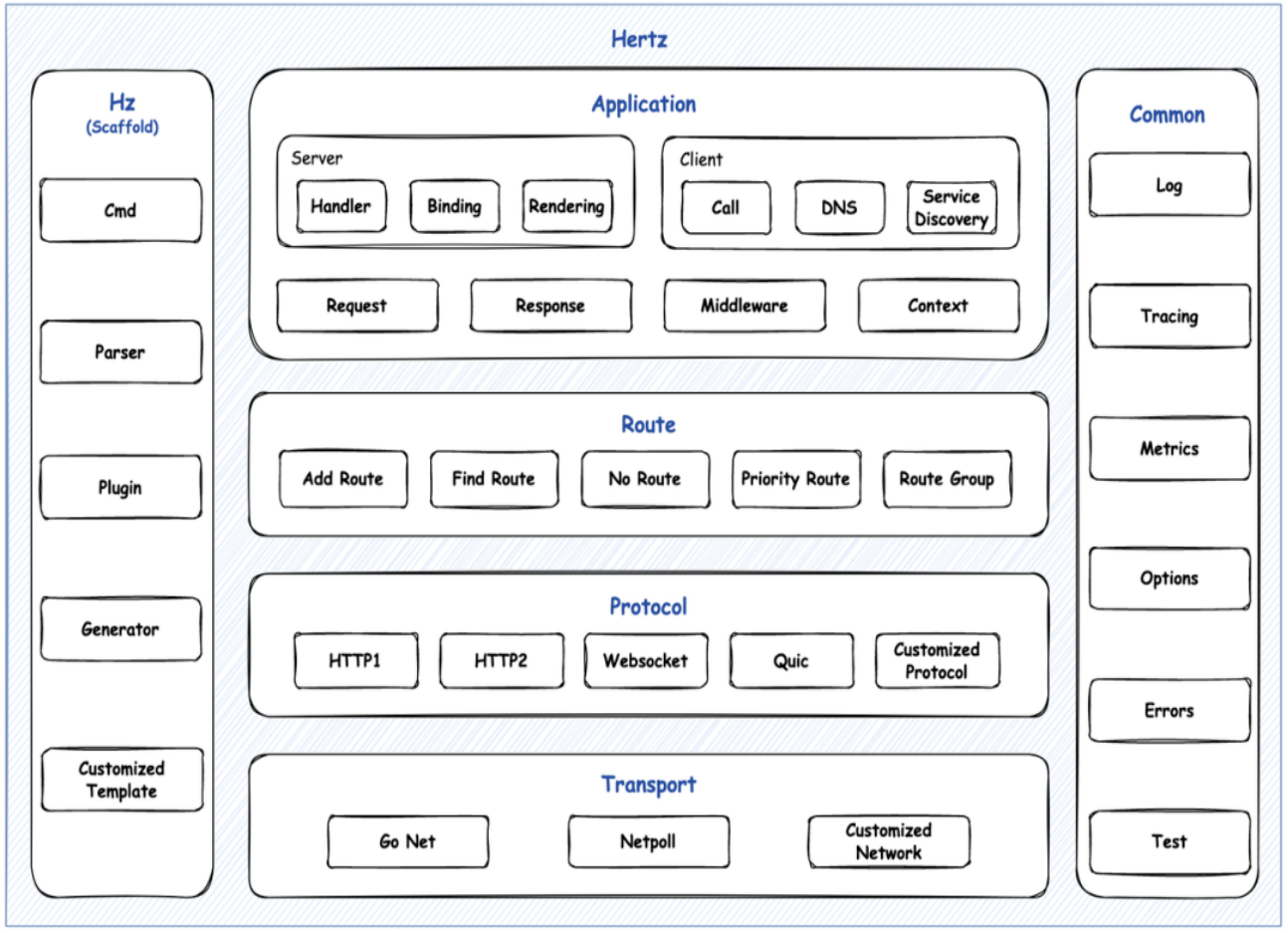
Hertz 从上到下分为:应用层、路由层、协议层和传输层,每一层各司其职,同时公共能力被统一抽象到公共层(common),做到跨层级复用。另外,同主库一同发布的还有作为子模块的 Hz 脚手架,它能够协助使用者快速搭建出项目核心骨架以及提供实用的构建工具链。
应用层
应用层是和用户直接交互的一层,提供丰富易用的 API,主要包括 Server、Client 和一些其他通用抽象。Server 提供了注册 HandlerFunc、Binding、Rendering 等能力;Client 提供了调用下游和服务发现等能力;以及抽象一个 HTTP 请求所必须涉及到的请求(Request)、响应(Response)、上下文(RequestContext)、中间件(Middleware)等等。Hertz 的 Server 和 Client 都能够提供中间件这样的扩展能力。
应用层中一个非常重要的抽象就是对 Server HandlerFunc 的抽象。早期,Hertz 路由的处理函数 (HandlerFunc)中并没有接收标准的 context.Context,我们在大量的实践过程中发现,业务方通常需要一个标准的上下文在 RPC Client 或者日志、Tracing 等组件间传递,但由于请求上下文(RequestContext)生命周期局限于一次 HTTP 请求之内,而以上提到的场景往往存在异步的传递和处理,导致如果直接传递请求上下文,会导致出现一些数据不一致的问题。为此我们做了诸多尝试,但是因为核心原因在于请求上下文(RequestContext)的生命周期无法优雅的按需延长,最终在各种设计权衡下,我们在路由的处理函数签名中增加一个标准的上下文入参,通过分离出生命周期长短各异的两个上下文的方式,从根本上解决各种因为上下文生命周期不一致导致的异常问题,即:
type HandlerFunc func(c context.Context, ctx *app.RequestContext)
路由层
路由层负责根据 URI 匹配对应的处理函数。
起初,Hertz 的路由基于 httprouter 开发,但随着使用的用户越来越多,httprouter 渐渐不能够满足需求,主要体现在 httprouter 不能够同时注册静态路由和参数路由,即 /a/b,/:c/d 这两个路由不能够同时注册;甚至有一些更特殊的需求,如/a/b、/:c/b ,当匹配 /a/b 路由时,两个路由都能够匹配上。
Hertz 为满足这些需求重新构造了路由树,用户在注册路由时拥有很高的自由度:支持静态路由、参数路由的注册;支持按优先级匹配,如上述例子会优先匹配静态路由 /a/b ;支持路由回溯,如注册 /a/b、/:c/d,当匹配 /a/d 时仍然能够匹配上;支持尾斜线重定向,如注册 /a/b,当匹配 /a/b/ 时能够重定向到 /a/b 上。Hertz 提供了丰富的路由能力来满足用户的需求,更多的功能可以参考 Hertz 配置文档。

协议层
协议层负责不同协议的实现和扩展。
Hertz 支持协议的扩展,用户只需要实现下面的接口便可以按照自己的需求在引擎(Engine) 上扩展协议,同时也支持通过 ALPN 协议协商的方式注册。Hertz 首批只开源了 HTTP1 实现,未来会陆续开源 HTTP2、QUIC 等实现。协议层扩展提供的灵活性甚至可以超越 HTTP 协议的范畴,用户完全可以按需注册任意符合自身需求的协议层实现,并且加入到 Hertz 的引擎中来,同时,也能够无缝享受到传输层带来的极致性能。
type ServerFactory interface {
New(core Core) (server protocol.Server, err error)
}
type Server interface {
Serve(c context.Context, conn network.Conn) error
}
传输层
传输层负责底层的网络库的抽象和实现。
Hertz 支持底层网络库的扩展。Hertz 原生完美适配 Netpoll,在时延方面有很多深度的优化,非常适合时延敏感的业务接入。Netpoll 对 TLS 能力的支持有待完善,而 TLS 能力又是 HTTP 框架必备能力,为此 Hertz 底层同时支持基于 Golang 标准网络库的实现适配,支持网络库的一键切换,用户可根据自己的需求选择合适的网络库进行替换。如果用户有更加高效的网络库或其他网络库需求,也完全可以根据需求自行扩展。
Hz 脚手架
与 Hertz 一并开源的还有一个易用的命令行工具 Hz,用户只需提供一个 IDL,根据定义好的接口信息,Hz 便可以一键生成项目脚手架,让 Hertz 达到开箱即用的状态;Hz 也支持基于 IDL 的更新能力,能够基于 IDL 变动智能地更新项目代码。目前 Hz 支持了 Thrift 和 Protobuf 两种 IDL 定义。命令行工具内置丰富的选项,可以根据自己的需求使用。同时它底层依赖 Protobuf 官方的编译器和自研的 Thriftgo 的编译器,两者都支持自定义的生成代码插件。如果默认模板不能够满足需求,完全能够按需定义。
未来,我们将继续迭代 Hz,持续集成各种常用的中间件,提供更高层面的模块化构建能力。给 Hertz 的用户提供按需调整的能力,通过灵活的自定义配置打造一套满足自身开发需求的脚手架。
Common 组件
Common 组件主要存放一些公共的能力,比如错误处理、单元测试能力、可观测性相关能力(Log、Trace、Metrics 等)。对于服务可观测性的能力,Hertz 提供了默认的实现,用户可以按需装配;如果用户有特殊的需求,也可以通过 Hertz 提供的接口注入。比如对于 Trace 能力,Hertz 提供了默认的实现,也提供了将 Hertz 和 Kitex 串起来的 Example。如果想注入自己的实现,也可以实现下面的接口:
复制
// Tracer is executed at the start and finish of an HTTP.
type Tracer interface {
Start(ctx context.Context, c *app.RequestContext) context.Context
Finish(ctx context.Context, c *app.RequestContext)
}
Hertz 中间件
Hertz 除了提供 Server 的中间件能力,还提供了 Client 中间件能力。用户可以使用中间件能力将通用逻辑(如:日志记录、性能统计、异常处理、鉴权逻辑等等)和业务逻辑区分开,让用户更加专注于业务代码。Server 和 Client 中间件使用方式相同,使用 Use 方法注册中间件,中间件执行顺序和注册顺序相同,同时支持预处理和后处理逻辑。

Server 和 Client 的中间件实现方式并不相同。对于 Server 来说,我们希望减少栈的深度,同时也希望中间件能够默认的执行下一个,用户需要手动终止中间件的执行。因此,我们将 Server 的中间件分成了两种类型,即不在同一个函数调用栈(该中间件调用完后返回,由上一个中间件调用下一个中间件,如图 2 中 B 和 C)和在同一个函数调用栈的中间件(该中间件调用完后由该中间件继续调用下一个中间件,如图 2 中 C 和 Business Handler)。
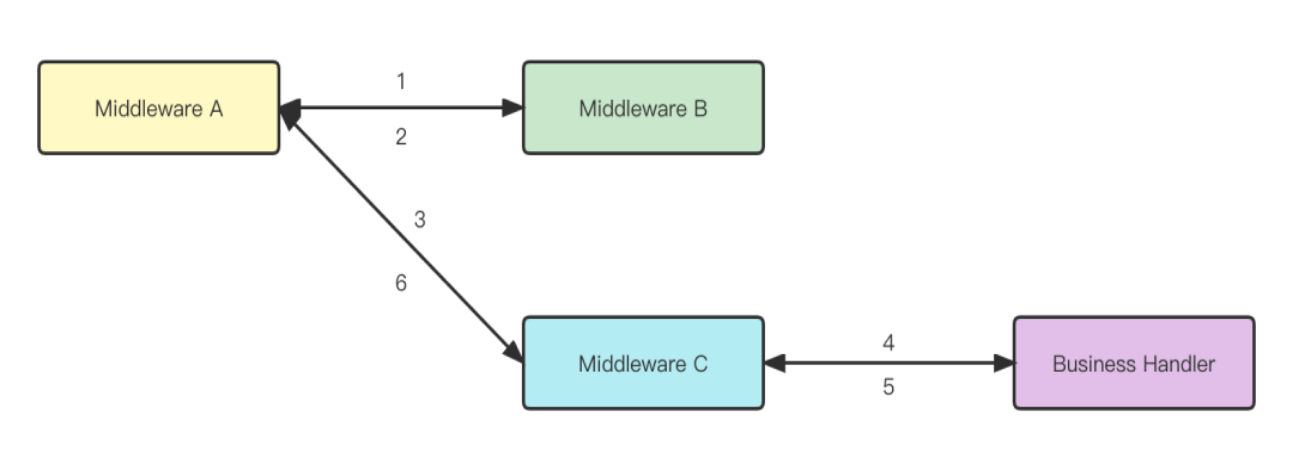
其核心是需要一个地方存下当前的调用位置 index,并始终保持其递增。恰好 RequestContext 就是一个存储 index 合适的位置。但是对于 Client,由于没有合适的地方存储 index,我们只能退而求其次,抛弃 index 的实现,将所有的中间件构造在同一调用链上,需要用户手动调用下一个中间件。
Hertz代码生成工具


Hertz 性能
hertz 的性能非常不错
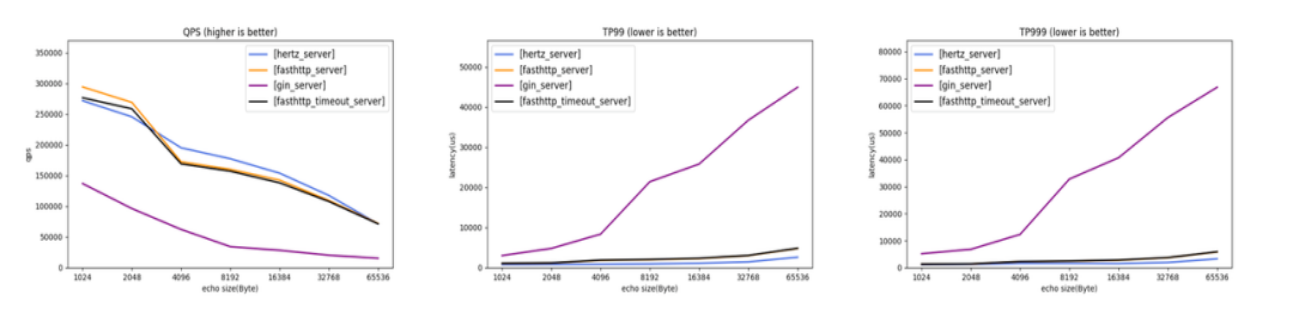
Hertz 使用字节跳动自研高性能网络库 Netpoll,在提高网络库效率方面有诸多实践,参考已发布文章字节跳动在 Go 网络库上的实践。除此之外,Netpoll 还针对 HTTP 场景进行优化,通过减少拷贝和系统调用次数提高吞吐以及降低时延。为了衡量 Hertz 性能指标,我们选取了社区中有代表性的框架 Gin(net/http)和 Fasthttp 作为对比,可以看到,Hertz 的极限吞吐、TP99 等指标均处于业界领先水平。未来,Hertz 还将继续和 Netpoll 深度配合,探索 HTTP 框架性能的极限。

笔记项目
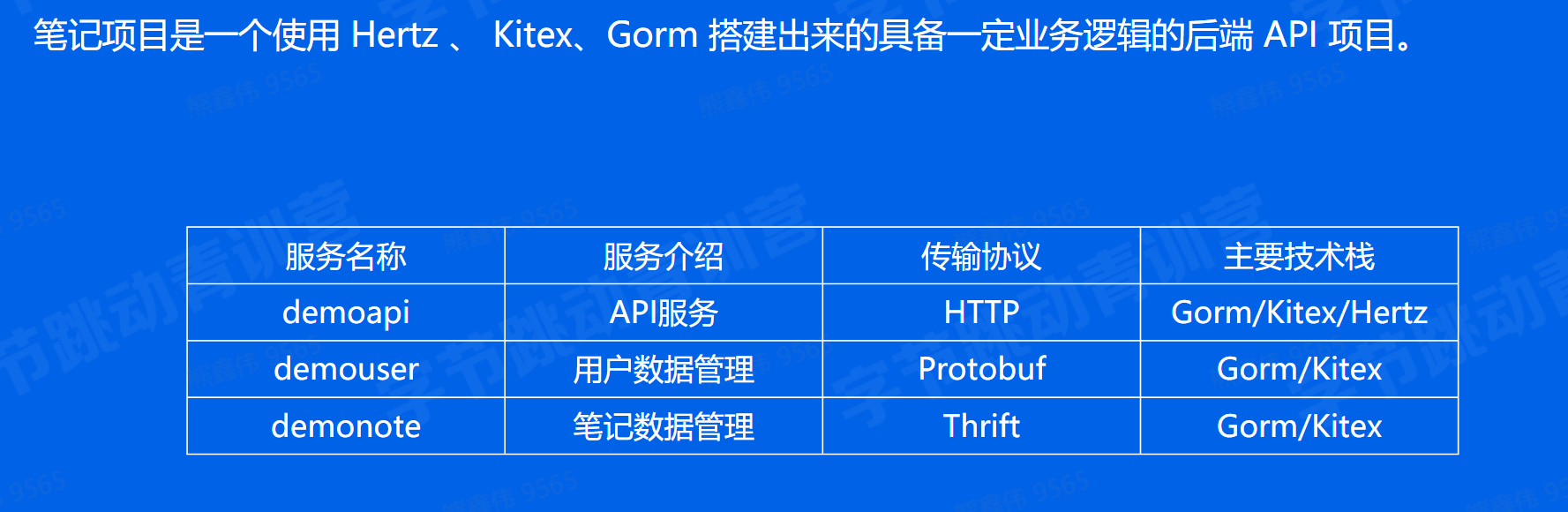
| Service Name | Usage | Framework | protocol | Path | IDL |
|---|---|---|---|---|---|
| demoapi | http interface | kitex/hertz | http | bizdemo/easy_note/cmd/api | |
| demouser | user data management | kitex/gorm | protobuf | bizdemo/easy_note/cmd/user | bizdemo/easy_note/idl/user.proto |
| demonote | note data management | kitex/gorm | thrift | bizdemo/easy_note/cmd/note | bizdemo/easy_note/idl/note.thrift |
项目模板:
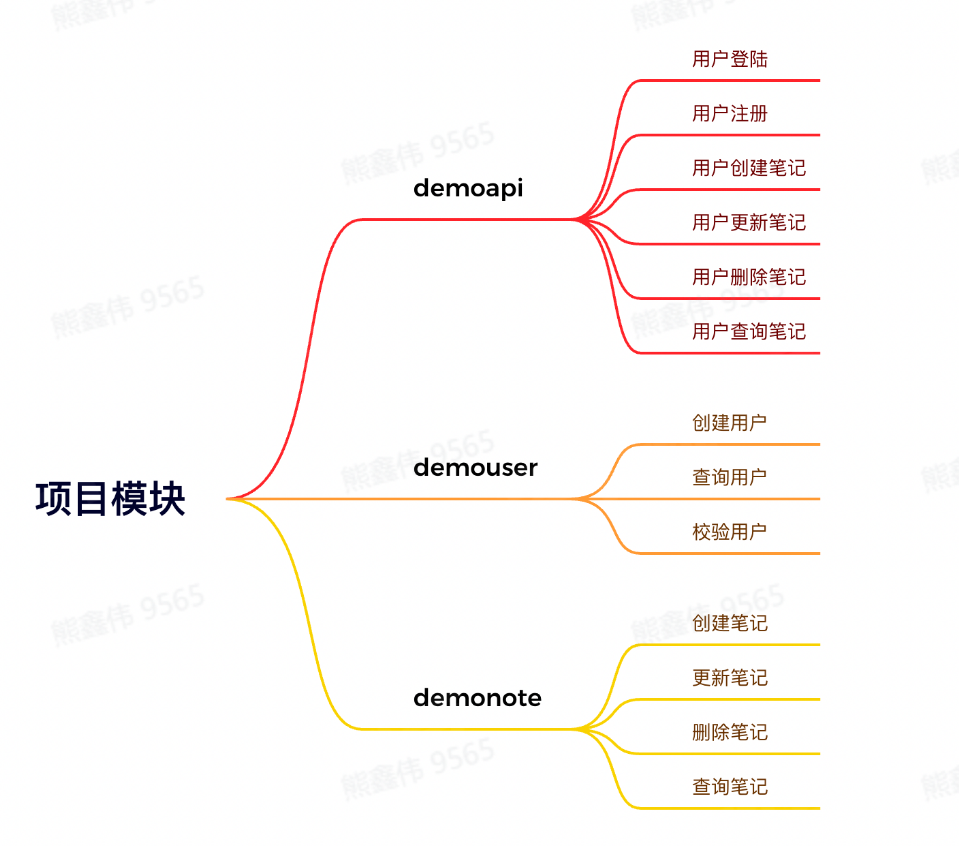
项目调用关系:
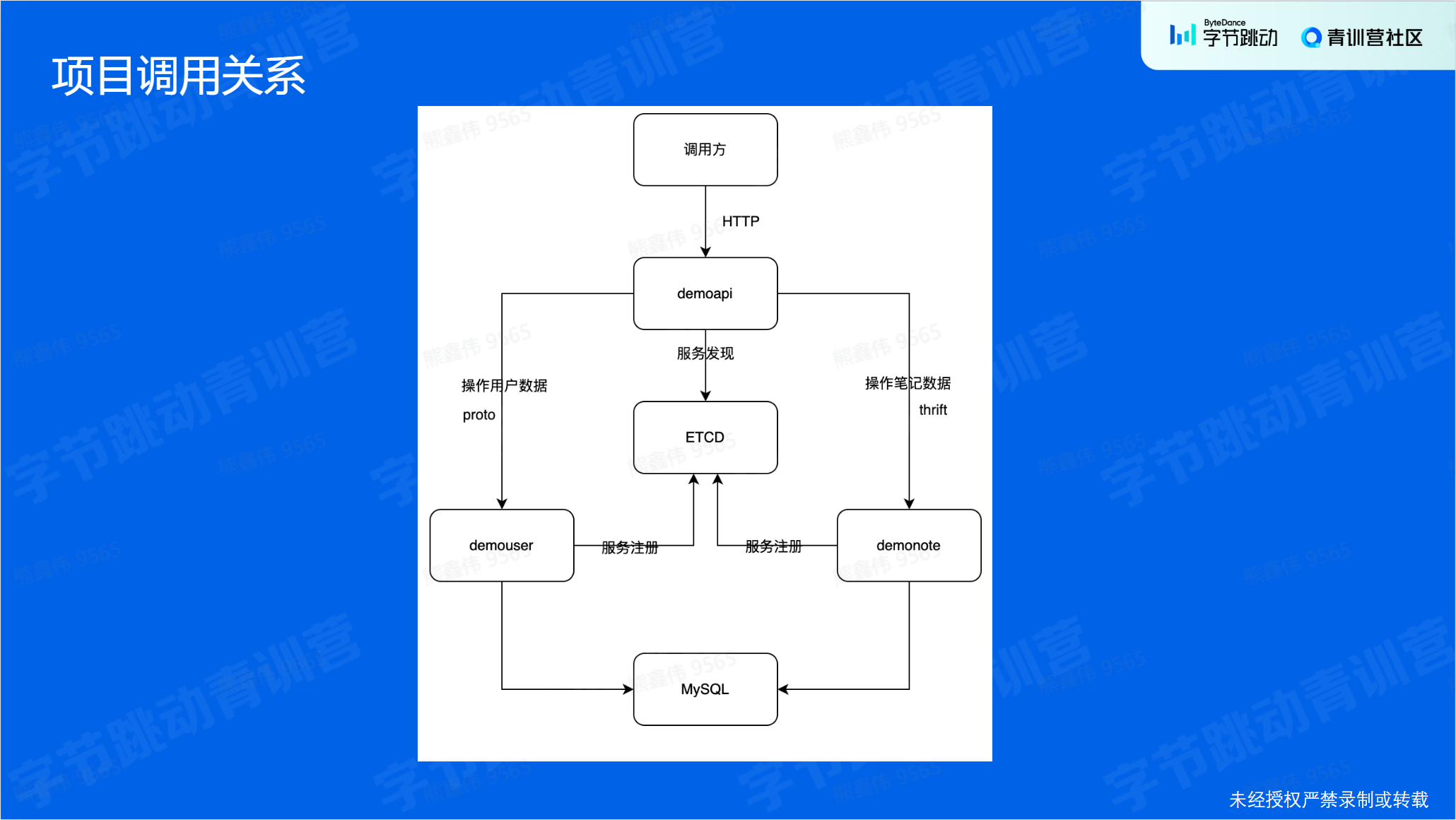
API 并不是和数据库打交道的,这样好处是可以复用接口,可扩展性强。
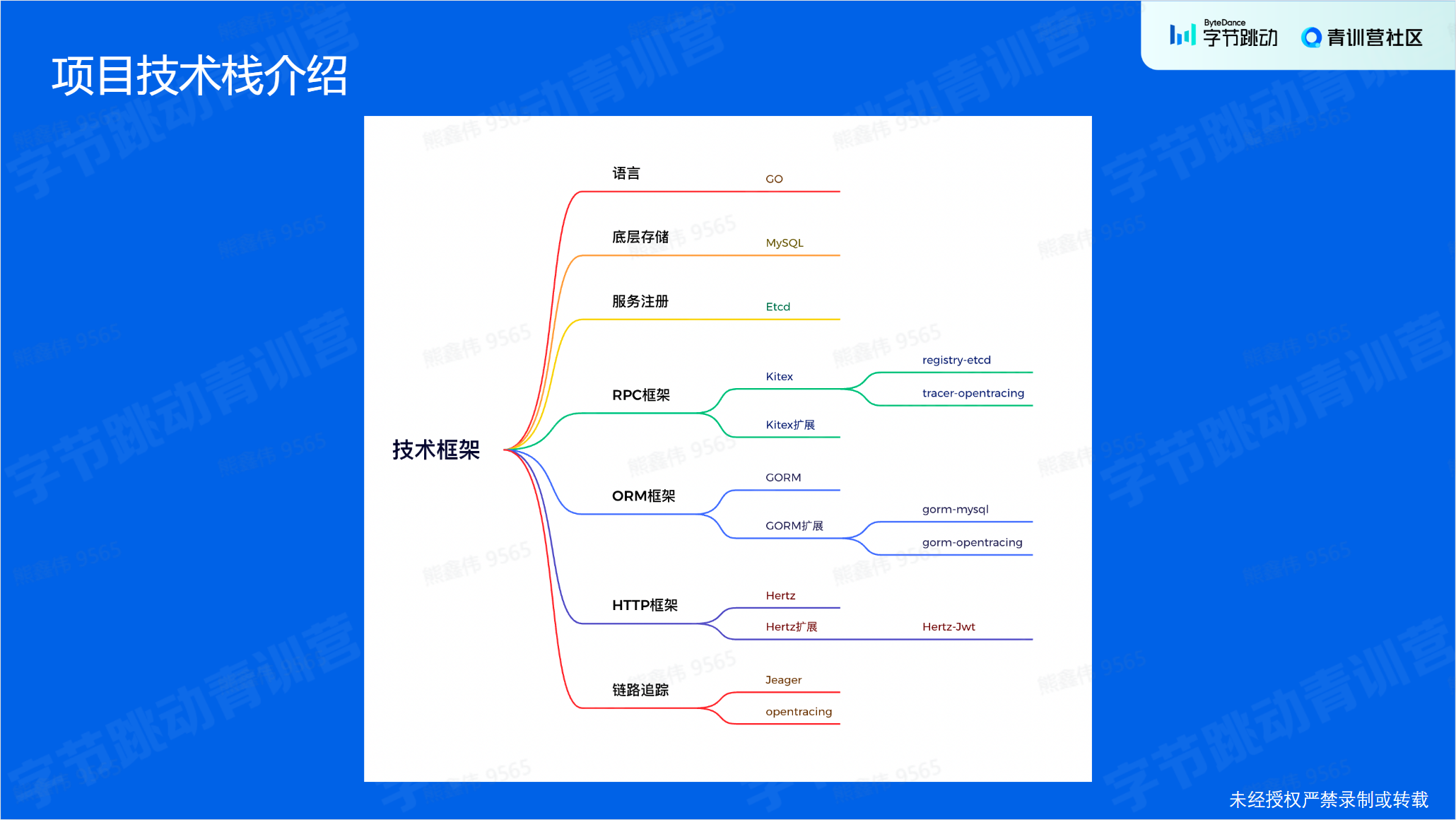
技术栈: