第28节 高质量编程简介及编码规范
❤️💕💕Go语言高级篇章,在此之前建议您先了解基础和进阶篇。Myblog:http://nsddd.top
Go语言基础篇
Go语言100篇进阶
[TOC]
准备
高质量代码
编写的代码达到正确的、可靠的、简介清晰的目标可称之为高质量代码。
- 边界条件(错误调用处理)
- 异常情况处理
- 易读易维护

注释
- 注释解释代码的作用
- 注释解释代码如何做的
- 注释解释代码实现的原因
- 注释解释代码在什么情况下会出错
好的代码有很多注释,坏的代码需要很多注释。
命名规范
规范:
- 包名应该是小写字母,不能包含下划线或者短横线。
- 变量名和函数名应该是小写字母,如果名字由多个单词组成,则每个单词之间应该使用驼峰式命名。
- 类型名和接口名应该是大写字母,如果名字由多个单词组成,则每个单词之间应该使用驼峰式命名。
- 常量名应该全部大写,如果名字由多个单词组成,则每个单词之间应该使用下划线连接。
- 变量名和函数名不能以下划线或短横线开头。
- 不能使用与Go语言关键字相同的名字。
- 注意缩略词全大写,位于开头的话可以全小写(HTTP、XML)

函数命名规范
在 Go 语言中,函数命名规范如下:
- 函数名应该是小写字母,如果名字由多个单词组成,则每个单词之间应该使用驼峰式命名,首字母小写。
- 函数名不能以下划线或短横线开头。
- 不能使用与Go语言关键字相同的名字。
- 函数名不能缩写,应该使用全称。
- 函数名应该能够清楚地描述函数的功能。
包的规范
在 Go 语言中,包名命名规范如下:
- 包名应该是小写字母,不能包含下划线或者短横线。
- 包名应该能够清楚地描述该包的功能。
- 包名应该尽量短,并且避免使用缩写。
- 包名应该尽量避免和其他包名相同。
- 包名应该是全局唯一的, 不能和其他任何已经发布的包或者其他项目重名。
- 包名不能与Go语言关键字相同。
- 包名不能以下划线或短横线开头。
注意:Go语言默认支持在线安装包,所以包名必须是全局唯一的, 建议使用公司或者组织名称作为包名的前缀。

错误和异常处理

errors.New 函数是 Go 语言标准库中定义的一个函数,它用于创建一个新的错误。该函数接受一个字符串作为参数,该字符串描述了错误的原因。这个函数会返回一个实现了 error 接口的对象,可以在程序中使用这个对象来报告错误。
package main
import (
"fmt"
"errors"
)
func main() {
_, err := divide(10, 0)
if err != nil {
fmt.Println(err)
}
}
func divide(a, b int) (int, error) {
if b == 0 {
return 0, errors.New("cannot divide by zero")
}
return a / b, nil
}
🚀 编译结果如下:
cannot divide by zero
在上面的程序中,divide函数检查分母是否为0,如果是,则使用errors.New函数创建了一个新的错误,描述了错误原因为“cannot divide by zero”.在main函数中,使用if语句判断返回值是否为错误,如果是,则输出错误信息.
记住,errors.New 不会添加额外的调试信息到错误中,如果需要添加更多的信息,可以使用 fmt.Errorf 函数.

fmt.Errorf 函数是 Go 语言标准库中定义的一个函数,它用于格式化错误信息并创建一个新的错误。该函数接受一个格式字符串和一些参数作为参数,格式字符串描述了错误的原因,参数用于替换格式字符串中的占位符。这个函数会返回一个实现了 error 接口的对象,可以在程序中使用这个对象来报告错误。
package main
import (
"fmt"
)
func main() {
_, err := divide(10, 0)
if err != nil {
fmt.Println(err)
}
}
func divide(a, b int) (int, error) {
if b == 0 {
return 0, fmt.Errorf("cannot divide %d by %d", a, b)
}
return
}
🚀 编译结果如下:
PS D:\文档\my\go-pprof-practice> go run .\test.go
cannot divide 10 by 0
性能优化
如何评估:
- 性能表现需要实际数据说明
- Go语言提供了支持基准性能测试benchmark工具
go test -bench=. -benchmen
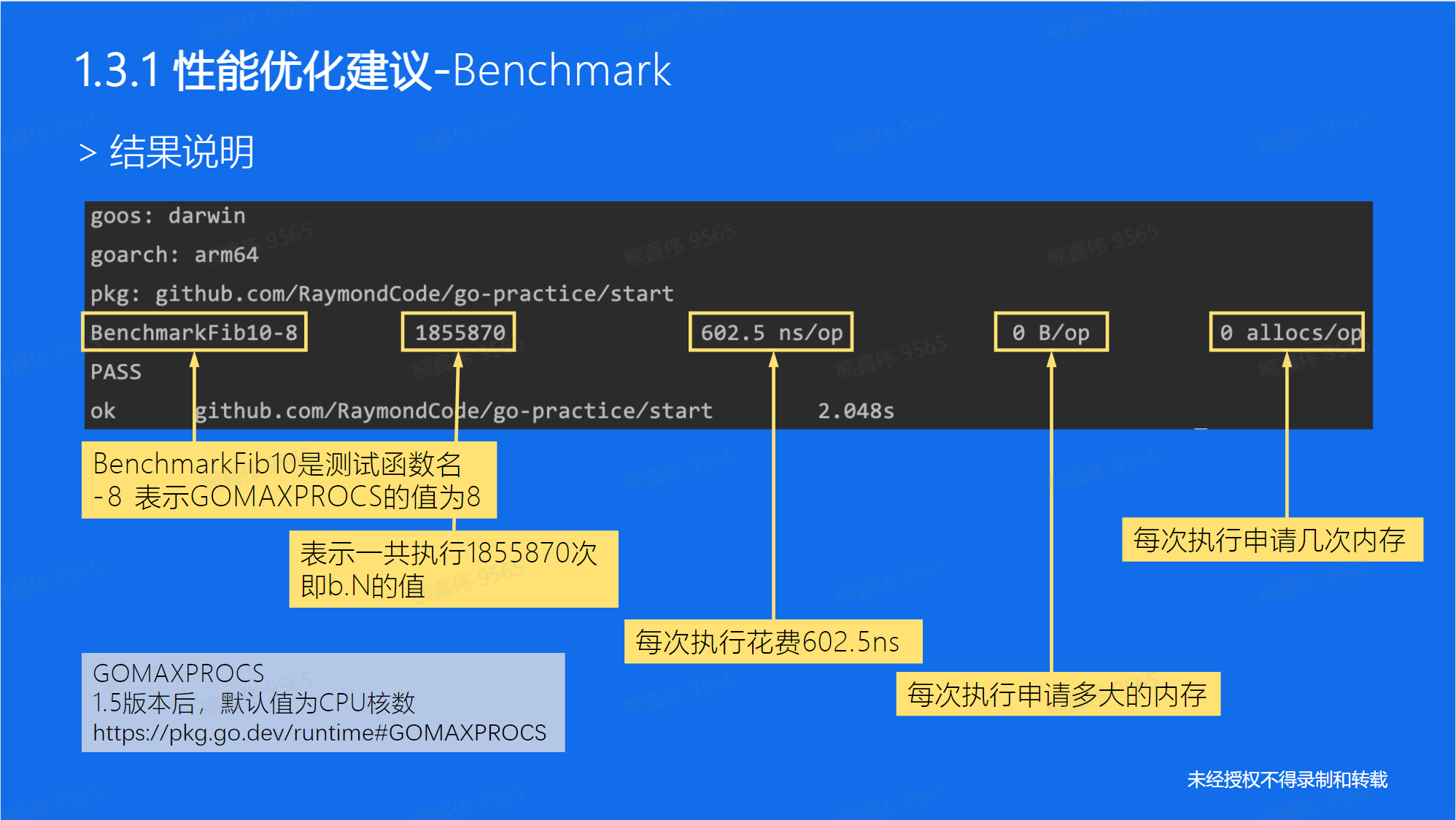
程序在初始化的时候指定大小,可以看到执行时间是之前的 1/3 大小。

这个和底层数据结构相关的。
🤔 可以看到当容量不够的时候,底层是先有一次扩容 (✖2)操作,然后再添加,消耗时间~
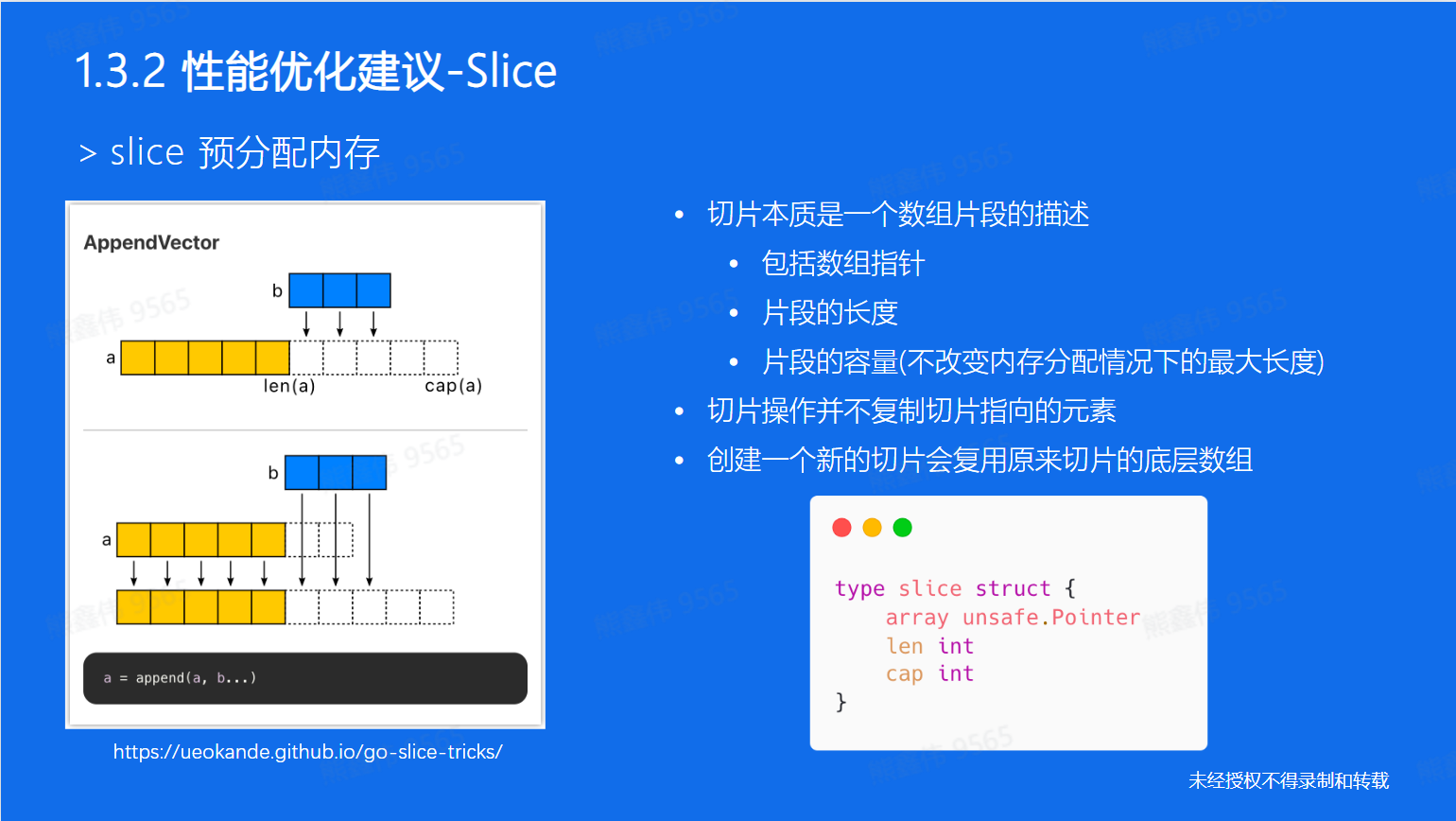
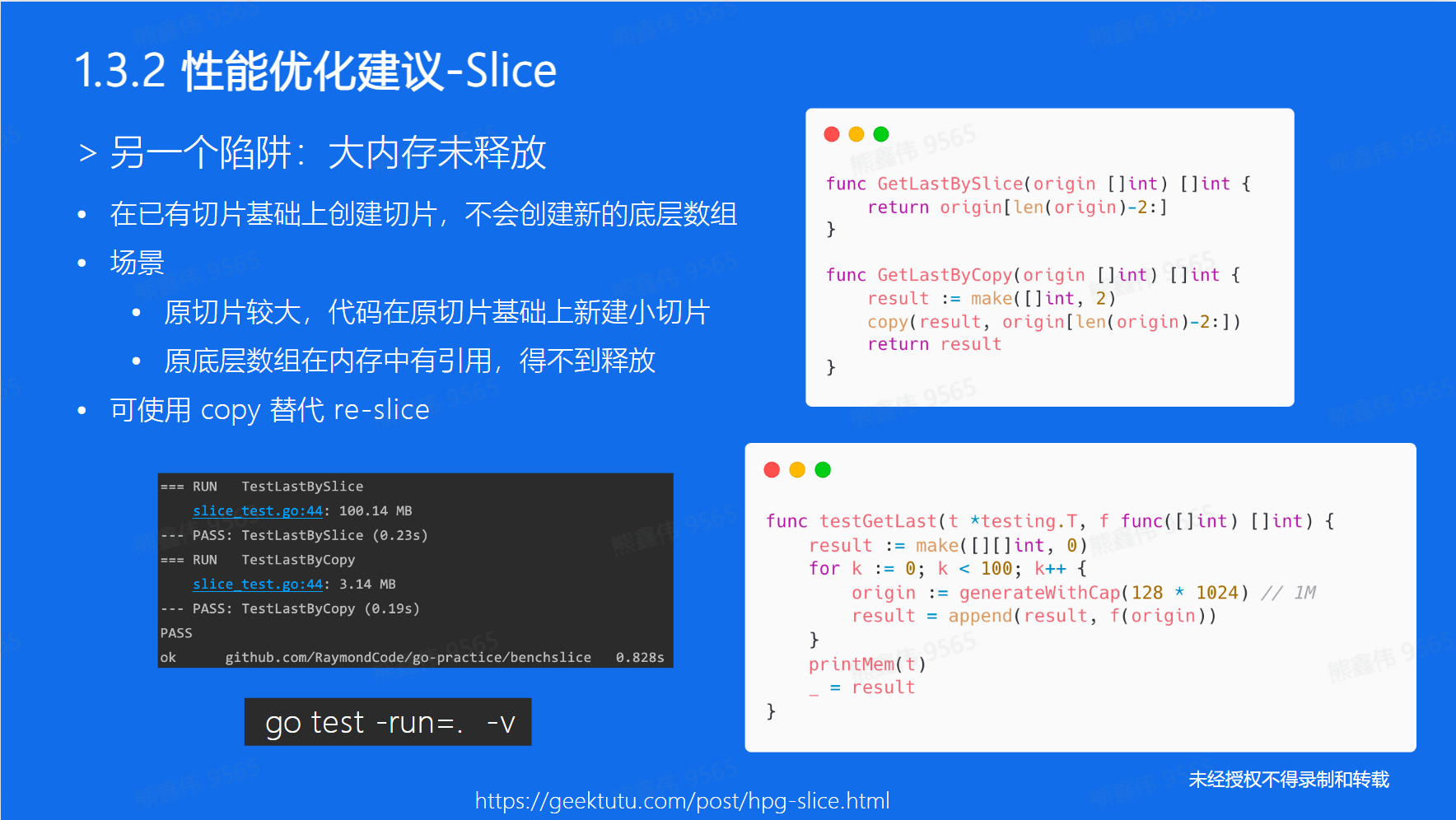
大内存未释放
切片是引用的一段空间,所以原底层再内存中的引用得不到释放。
在 Go 语言中,使用 copy 函数可以避免重新切片 (re-slice) 造成的性能问题。
重新切片是指对一个已经存在的切片进行切片操作,这样会导致新的内存分配,从而降低程序的性能。
当我们重新切片一个已经存在的切片时,如果新切片的长度或容量超过了原切片的长度或容量,则需要重新分配内存来容纳新切片。这样会导致新的内存分配,从而降低程序的性能。
需要注意的是,当重新切片的长度和容量小于等于原切片的长度和容量时,则不会进行重新分配内存的操作。
而使用copy函数复制数据可以避免这个问题,因为它只是将数据从一个切片复制到另一个切片,不会导致内存的重新分配.
使用 copy 函数可以避免这个问题。 copy 函数接受两个参数,分别是目标切片和源切片,它会将源切片中的数据复制到目标切片中,而不是新分配内存。
package main
import (
"fmt"
)
func main() {
// 定义一个切片
s := []int{1, 2, 3, 4, 5}
// 使用重新切片操作,复制s的前3个元素到s1
s1 := s[:3]
//使用copy函数,复制s的前3个元素到s2
s2 := make([]int, 3)
copy(s2, s[:3])
fmt.Println(s1)
fmt.Println(s2)
}
使用 copy 函数复制数据可以节省内存的分配和垃圾回收的时间,提高性能。
注意,copy 函数只能复制切片的数据,不能复制切片的底层数组。如果需要复制底层数组,可以使用其他方法如 append 函数来实现。
map优化建议
和slice 类似:
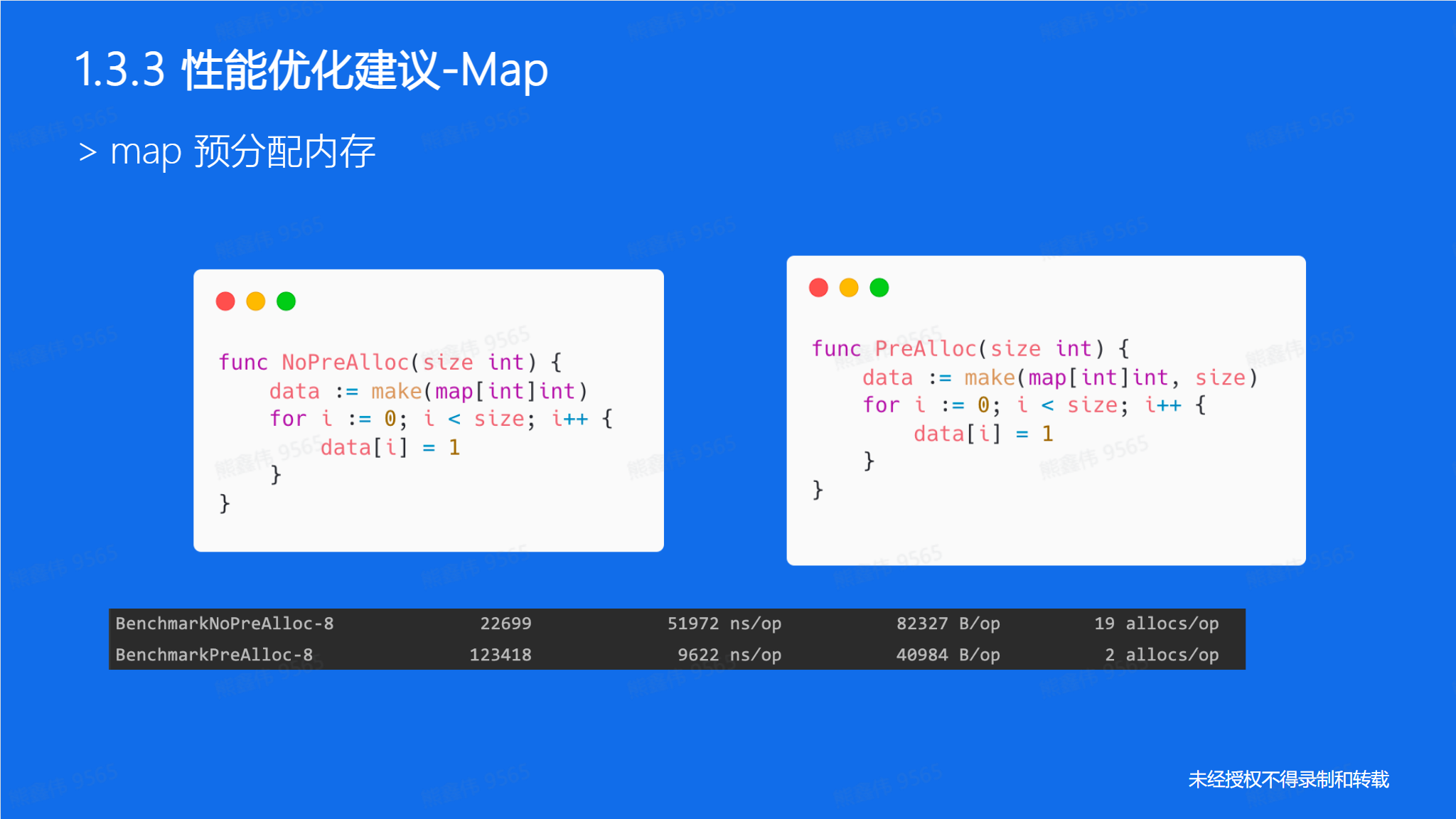
分配内存建议:

字符串处理,优化
不同拼接字符串的方法对应的性能有差异:


Go语言中常见的拼接字符串的方式有以下几种:
使用 + 运算符:
s1 := "Hello"
s2 := "World"
s3 := s1 + " " + s2
fmt.Println(s3) // "Hello World"
使用 fmt.Sprintf 函数:
Copy codes1 := "Hello"
s2 := "World"
s3 := fmt.Sprintf("%s %s", s1, s2)
fmt.Println(s3) // "Hello World"
使用 strings.Join 函数:
s := []string{"Hello", "World"}
s3 := strings.Join(s, " ")
fmt.Println(s3) // "Hello World"
使用 bytes.Buffer:
var buffer bytes.Buffer
buffer.WriteString("Hello")
buffer.WriteString(" ")
buffer.WriteString("World")
s3 := buffer.String()
fmt.Println(s3) // "Hello World"
在结合你的具体需求来选择合适的方式来拼接字符串。
在拼接字符串数量较多时,使用 fmt.Sprintf, strings.Join 以及 bytes.Buffer 是更优秀的选择。 而在拼接字符串数量较少时,使用 + 运算符是比较简单直接的选择。
需要注意的是,在使用 + 运算符拼接字符串时,如果字符串数量较多,会产生大量的临时对象,导致频繁的内存分配和垃圾回收,影响性能。而使用 fmt.Sprintf, strings.Join 以及 bytes.Buffer 不会有这个问题。
另外,在处理大量数据时,使用 bytes.Buffer 效率更高,因为它是基于字节的,而不是基于字符的。
总之,在选择字符串拼接的方式时,要考虑到字符串的数量、性能和可读性等因素。

但是bytes.Buffer和strings.builder底层区别也影响了它们的性能:
- bytes.Buffer是基于字节的,内部使用一个动态数组来存储字节。它提供了一些方法来操作字节,如 Write, WriteString, WriteByte 等。
- strings.Builder 是基于字符的,内部使用一个动态数组来存储字符。它提供了一些方法来操作字符,如 Write, WriteString, WriteByte 等。
- 在性能上,bytes.Buffer 和 strings.Builder 的性能差异不大,但是在处理大量字节数据时,bytes.Buffer 会更快一些,因为它是基于字节的。 而strings.Builder 更适合处理字符数据。
- 在选择使用bytes.Buffer 和 strings.Builder 时,要根据你的具体需求,如果你需要处理大量字节数据,使用 bytes.Buffer 更加合适。如果处理的是字符串,使用strings.Builder 更加合适。
- 需要注意的是,在Go 1.13版本之后,strings.Builder 已经成为了标准库中的标准字符串拼接方式。
空结构体 占位符
在 Go 语言中,空结构体 (empty struct) 可以被用作占位符。空结构体是一种特殊的结构体,它没有任何字段,也就是说它没有任何内存占用。
这种用途常用在 channel 上, 因为空结构体占用内存最小,可以高效地在 channel 上传递信号。
💡简单的一个案例如下:
package main
import "fmt"
func main() {
done := make(chan struct{})
go func() {
fmt.Println("Doing some work...")
close(done)
}()
fmt.Println("Waiting for work to be done...")
<-done
fmt.Println("Work done!")
}
🚀 编译结果如下:
PS D:\文档\my\go-pprof-practice> go run .\test.go
Waiting for work to be done...
Doing some work...
Work done!
📜 对上面的解释:
在这个例子中,我们使用了一个空结构体类型的 channel 来传递信号,当 goroutine 完成了工作之后就会向 channel 中发送一个空结构体,主 goroutine 通过读取 channel 中的数据来判断工作是否完成。
需要注意的是,由于空结构体不占用任何内存,所以它在 channel 中传递的是一个空消息,不能在 channel 中传递数据。
空结构体还有其它用途,例如作为占位符在 map 中使用、作为锁的实现等。

作为占位符在 map 中使用
作为占位符在 map 中使用,用来检查一个键是否存在:
m := make(map[string]struct{})
m["key1"] = struct{}{}
_, ok := m["key1"]
fmt.Println(ok) // true
_, ok = m["key2"]
fmt.Println(ok) // false
作为锁的实现,用来实现互斥操作
var lock struct{}
func myFunc() {
fmt.Println("Acquiring lock...")
lock = struct{}{}
fmt.Println("Lock acquired.")
// do some work
fmt.Println("Releasing lock...")
lock = struct{}{}
fmt.Println("Lock released.")
}
作为占位符在结构体中使用
用来减少结构体的内存占用。
💡简单的一个案例如下:
package main
import (
"fmt"
"unsafe"
)
type myStruct struct {
name string
data []byte
_ struct{}
}
type myStruct2 struct {
name string
data []byte
}
func main() {
s := myStruct{
name: "example",
data: []byte{1, 2, 3, 4, 5},
}
fmt.Println(s)
fmt.Printf("Size of myStruct: %d bytes\n\n", unsafe.Sizeof(s))
s2 := myStruct2{
name: "example2",
data: []byte{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
}
fmt.Println(s2)
fmt.Printf("Size of myStruct2: %d bytes\n", unsafe.Sizeof(s2))
}
🚀 编译结果如下:
{example [1 2 3 4 5] {}}
Size of myStruct: 48 bytes
{example2 [1 2 3 4 5 6 7 8 9 10]}
Size of myStruct2: 40 bytes
这里使用了空结构体作为占位符,减少了结构体的内存占用。
还有就是它可以用来标记某种类型, 例如:
type MyType struct{}
func (t MyType)DoSomething(){
// do something
}
var _ MyInterface = MyType{}
这样就可以避免编译错误。
总之, 空结构体作为占位符是一种高效的方式,在很多场景下都可以使用。
atomic包
Go语言的atomic包提供了一组原子操作函数,这些函数可以在并发环境中安全地更新基本数据类型,例如整型和浮点数。这些函数在底层使用了CPU的原子指令,可以保证在多线程环境中更新操作的原子性。
atomic包中提供了以下常用函数:
- AddInt32、AddInt64等:对指定的整型变量执行加法操作。
- CompareAndSwapInt32、CompareAndSwapInt64等:如果当前变量的值等于预期值,则将其设置为新值。
- LoadInt32、LoadInt64等:读取指定变量的值。
- StoreInt32、StoreInt64等:将指定变量设置为指定值。
请注意,atomic包中的函数仅适用于基本数据类型,如果需要对复杂数据类型进行原子操作,可以使用sync/atomic包中的函数。
实例:
package main
import (
"fmt"
"sync/atomic"
)
func main() {
var i int32 = 0
atomic.AddInt32(&i, 1)
fmt.Println(i) // 1
}
性能对比

使用actomic包

actomic保持线程安全
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var counter int64
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
atomic.AddInt64(&counter, 1)
}()
}
wg.Wait()
fmt.Println(counter)
}
🚀 编译结果如下:
100
这个例子中,我们创建了一个int64类型的变量counter,并在100个goroutine中并发地执行AddInt64函数对其进行自增操作。由于 AddInt64函数是原子的,所以不会发生竞态条件。在所有goroutine执行完毕后,counter的值应该为100,并且不会受到其它线程的影响。
性能优化分析工具
优化建议
Go语言性能调优有以下几点建议:
- 使用 Go 的内置性能分析工具,如 pprof,可以帮助诊断程序中的性能瓶颈。
- 避免使用高开销的操作,例如过多的内存分配和字符串连接。
- 使用 Go 协程,可以提高程序的并发性能。
- 使用 Go 的编译器优化,例如禁用内联(-gcflags=-l)和优化级别(-O)。
- 使用 Go 的原生并发类型,如 channel,而不是使用第三方库。
- 使用 Go 的垃圾回收器,可以减少内存分配和回收的开销。
- 尽量避免使用反射。
- 可以使用 cgo调用C语言代码来提升性能
优化原则:
- 优化最热点的代码: 通过性能分析工具(例如 pprof)来识别程序中的性能瓶颈并优化。
- 尽量减少不必要的操作: 比如内存分配、字符串连接等高开销操作。
- 使用合适的数据结构和算法: 例如使用 hash 表代替暴力查找,使用优化后的算法等。
- 使用并发和并行技术: 例如使用 Go 协程、channel 来提高程序的并发性能。
- 尽量避免使用反射: 使用反射会带来性能上的代价。
- 使用编译器优化: 例如禁用内联、使用优化级别等。
- 利用硬件加速: 例如使用 GPU 加速等。
- 优先使用高效的第三方库: 使用高效的第三方库可以减少代码量并提高性能。
- 经常进行性能测试和监控: 性能优化不是一次性的,需要经常进行性能测试和监控,及时发现并解决性能问题。
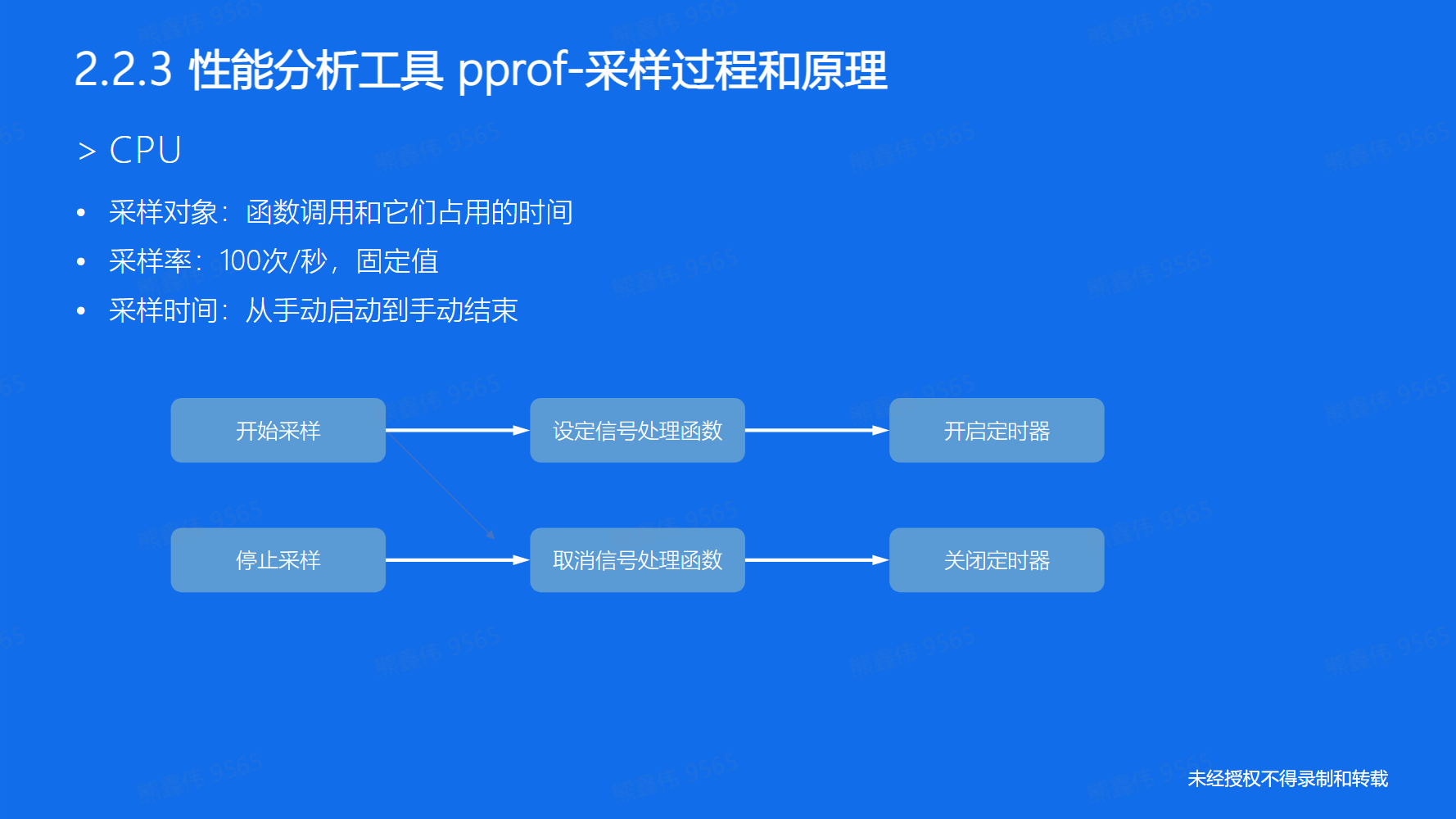
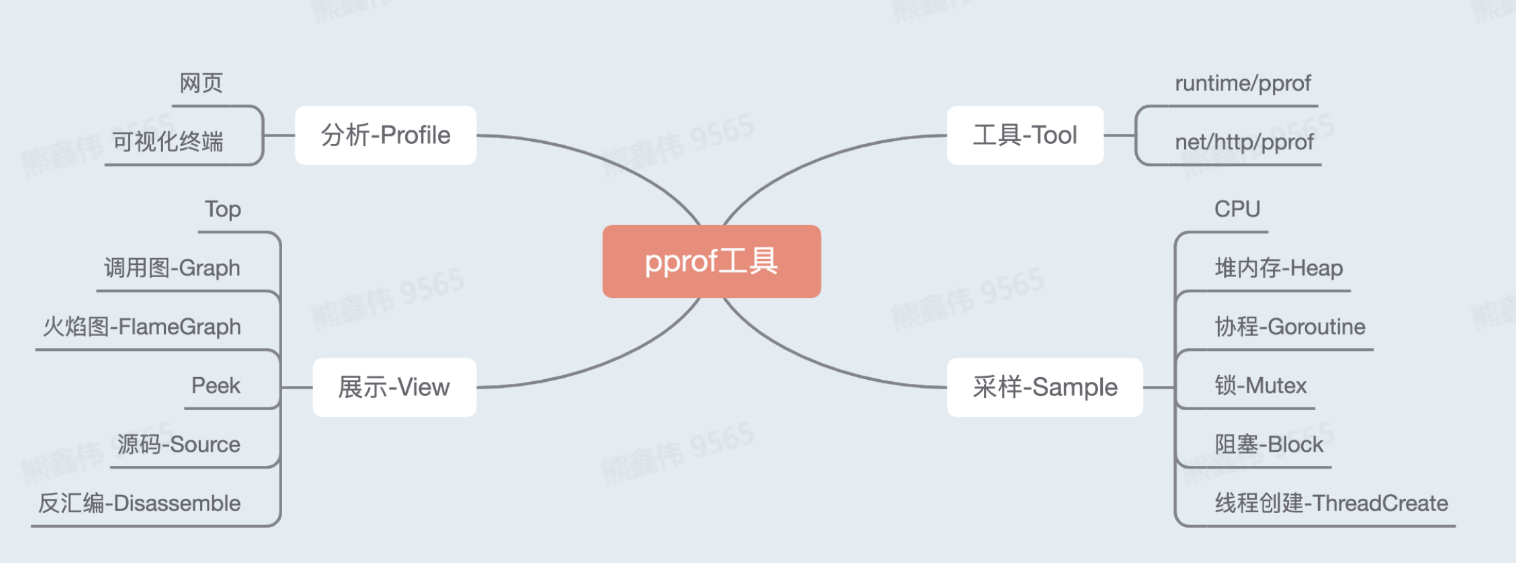
性能分析工具 pprof
pprof是 Go 语言的性能分析工具,它可以帮助诊断程序中的性能瓶颈。
使用方法:
- 在程序中导入 "net/http/pprof" 包
- 启动 pprof HTTP 服务器,通常是在 main 函数中调用
go func() { log.Println(http.ListenAndServe("localhost:6060", nil)) }() - 使用浏览器或命令行工具访问 pprof 的 HTTP 服务器,例如:
http://localhost:6060/debug/pprof/ - 通过 pprof 提供的不同的 web页面 或 命令行工具 查看性能统计信息
pprof 支持多种类型的性能分析,包括 CPU profile、memory profile、block profile、goroutine profile、threadcreate profile、heap profile等.
pprof项目实战
将最开始的项目 clone 到本地,在这个项目中,写了一些造成性能问题的代码炸弹。
编译并保持链接:
go run main.go
浏览器查看指标:
- http://localhost:6060/debug/pprof/
pprof命令排查:
保持连接,另开终端:
go tool pprof "http://localhost:6060/debug/pprof/profile?seconds=10"
topN — 查看占用资源最多的函数:
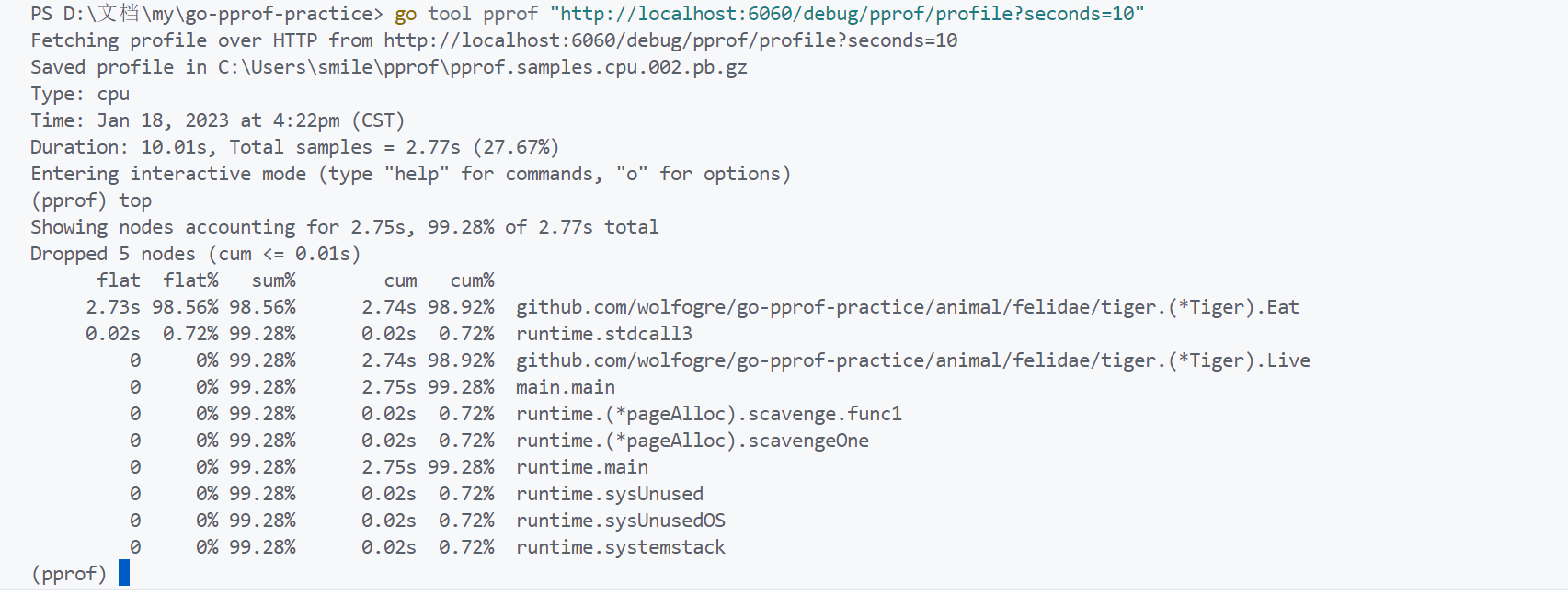
📜 对上面的解释:
- flat = cum,函数中没有调用其他的函数
- flat = 0,函数中只有其他函数的调用
list命令
(pprof) list Eat
Total: 2.77s
ROUTINE ======================== github.com/wolfogre/go-pprof-practice/animal/felidae/tiger.(*Tiger).Eat in D:\文档\my\go-pprof-practice\animal\felidae\tiger\tiger.go
2.73s 2.74s (flat, cum) 98.92% of Total
. . 19:}
. . 20:
. . 21:func (t *Tiger) Eat() {
. . 22: log.Println(t.Name(), "eat")
. . 23: loop := 10000000000
2.73s 2.74s 24: for i := 0; i < loop; i++ {
. . 25: // do nothing
. . 26: }
. . 27:}
. . 28:
. . 29:func (t *Tiger) Drink() {
(pprof)
问题出在第 24 L
调用关系可视化
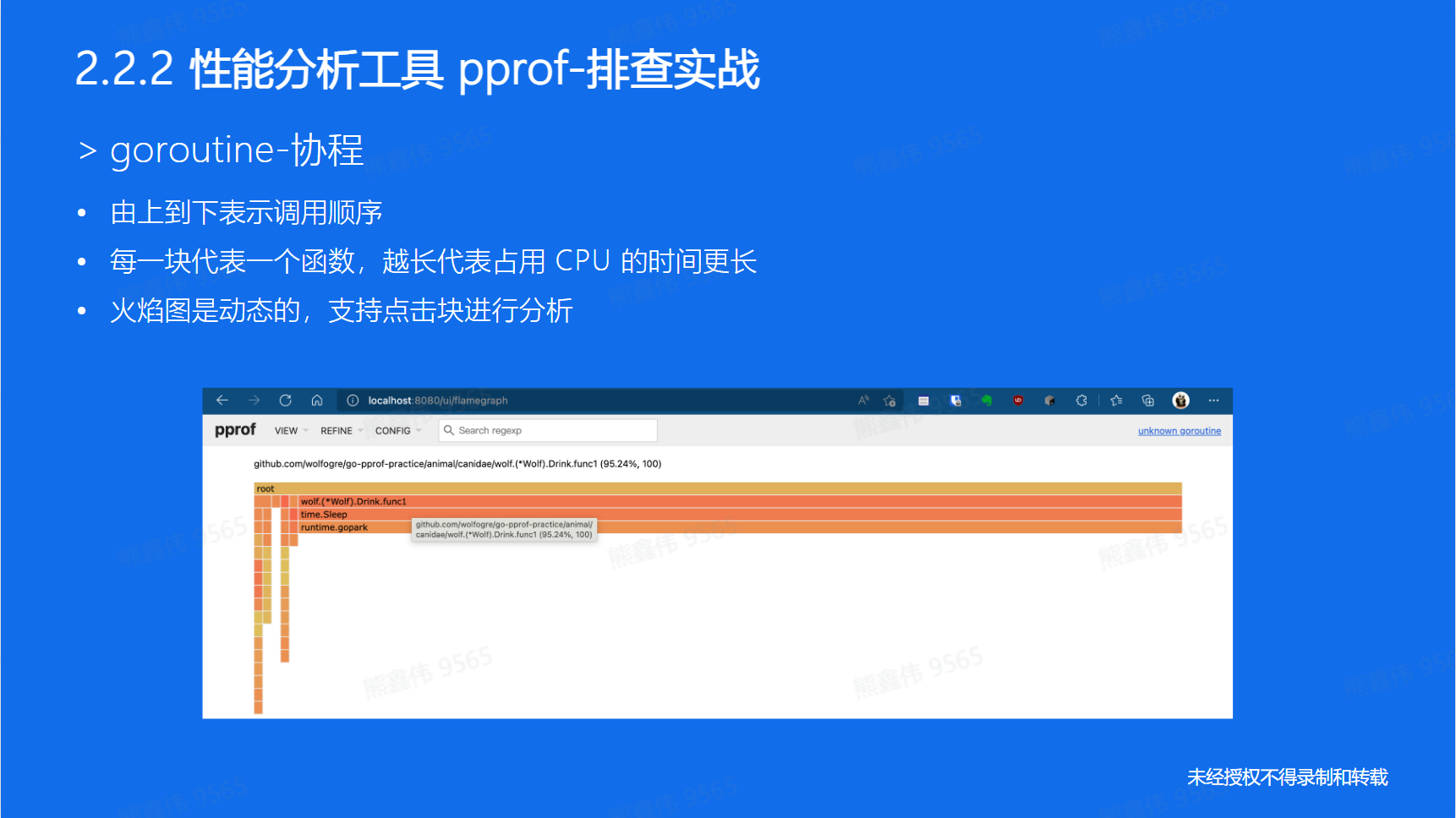
解决后,发现协程数下降:
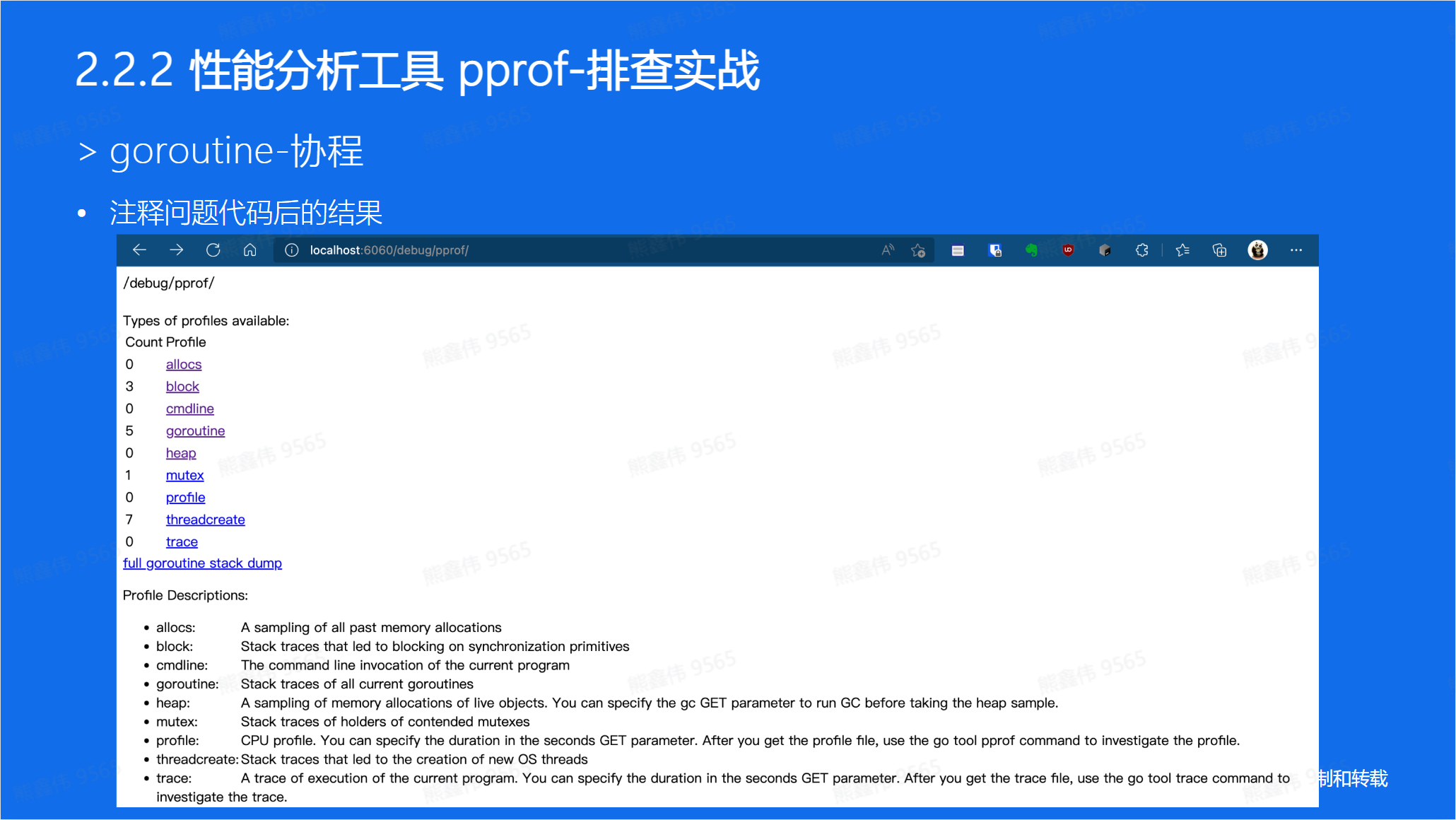
性能调优实战
pprof是性能调试工具,可以生成类似火焰图、堆栈图,内存分析图等。
整个分析的过程分为两步:1. 导出数据,2. 分析数据。
使用
allocs:查看过去所有内存分配的样本。
block:查看导致阻塞同步的堆栈跟踪。
cmdline: 当前程序的命令行的完整调用路径。
goroutine:查看当前所有运行的 goroutines 堆栈跟踪。
heap:查看活动对象的内存分配情况。
mutex:查看导致互斥锁的竞争持有者的堆栈跟踪。
profile: 默认进行 30s 的 CPU Profiling,得到一个分析用的 profile 文件。
threadcreate:查看创建新 OS 线程的堆栈跟踪。
trace:mp.weixin.qq.com/s/I9xSMxy32…
过程和原理