第25节 信息队列Kafka入门学习
❤️💕💕Go语言高级篇章,在此之前建议您先了解基础和进阶篇。Myblog:http://nsddd.top
Go语言基础篇
Go语言100篇进阶
[TOC]
参考文章
什么是Kafka
官方介绍:Apache Kafka 是一个开源分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和任务关键型应用程序。
维基:Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”,[4]这使它作为企业级基础设施来处理流式数据非常有价值。此外,Kafka可以通过Kafka Connect连接到外部系统(用于数据输入/输出),并提供了Kafka Streams——一个Java流式处理库。

消息系统
Kafka 和传统的消息系统(也称作消息中间件)都具备系统解耦、冗余存储、流量削峰、缓冲、异步通信、扩展性、可恢复性等功能。与此同时,Kafka 还提供了大多数消息系统难以实现的消息顺序性保障及回溯消费的功能。
存储系统
Kafka 把消息持久化到磁盘,相比于其他基于内存存储的系统而言,有效地降低了数据丢失的风险。也正是得益于 Kafka 的消息持久化功能和多副本机制,我们可以把 Kafka 作为长期的数据存储系统来使用,只需要把对应的数据保留策略设置 为“永久”或启用主题的日志压缩功能即可。
流式处理平台
Kafka 不仅为每个流行的流式处理框架提供了可靠的数据来源,还提供了一个完整的流式处理类库,比如窗口、连接、变换和聚合等各类操作。
Kafka基础概念
架构
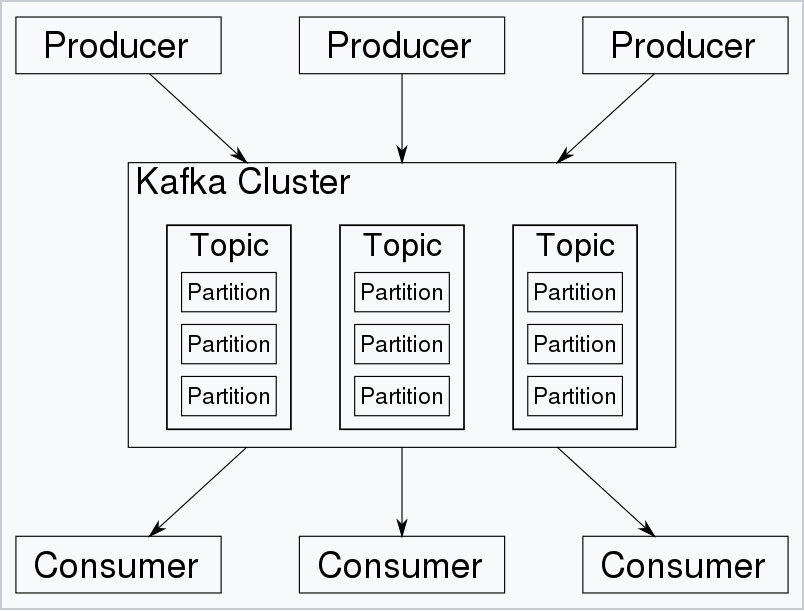
Kafka存储的消息来自任意多被称为“生产者”(Producer)的进程。数据从而可以被分配到不同的“分区”(Partition)、不同的“Topic”下。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为“消费者”(Consumer)的进程可以从分区查询消息。Kafka运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
Kafka高效地处理实时流式数据,可以实现与Storm、HBase和Spark的集成。作为聚类部署到多台服务器上,Kafka处理它所有的发布和订阅消息系统使用了四个API,即生产者API、消费者API、Stream API和Connector API。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如JMS、AMQP等。
Kafka架构的主要术语包括Topic、Record和Broker。Topic由Record组成,Record持有不同的信息,而Broker则负责复制消息。Kafka有四个主要API:
- 生产者API:支持应用程序发布Record流。
- 消费者API:支持应用程序订阅Topic和处理Record流。
- Stream API:将输入流转换为输出流,并产生结果。
- Connector API:执行可重用的生产者和消费者API,可将Topic链接到现有应用程序。
📜 对上面的解释:
- Topic 用来对消息进行分类,每个进入到Kafka的信息都会被放到一个Topic下
- Broker 用来实现数据存储的主机服务器
- Partition 每个Topic中的消息会被分为若干个Partition,以提高消息的处理效率
- Producer 消息的生产者
- Consumer 消息的消费者
- Consumer Group 消息的消费群组